
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 인공지능
- spark
- GDB
- Cypher
- r
- Federated Learning
- GSQL
- BigData
- Neo4j
- 딥러닝
- KnowledgeGraph #GraphThinking #Ontology #SemanticLayer #GraphRAG #DataGovernance #Neo4j #RDF #SHACL
- DeepLearning
- SparkML
- 그래프 데이터베이스
- 그래프 에코시스템
- 그래프
- Python
- TigerGraph
- GraphX
- RDD
- graph database
- RStudio
- graph
- 그래프 질의언어
- TensorFlow
- 빅데이터
- SQL
- 연합학습
- Graph Tech
- Graph Ecosystem
- Today
- Total
Hee'World
Spark RDD 본문
RDD는 스파크에서 가장 중요하고 핵심적인 기본 데이터 타입이라고 볼 수 있다. 스파크에서 처리되는 모든 데이터는 RDD를 기본으로 처리되고 실행된다.
RDD는 Resilient Distributed Dataset라고 불리며, 불변(변하지않는)하고 분산되는 데이터집합이라고 볼 수 있다.
스파크에서 각각의 데이터는 클러스터 메모리에 분산되어 Partition 단위로 분산 저장된다.

또한, 리니지(Lineage)라는 RDD 생성 단계를 기록하여 연산 처리 중, 노드의 장애 또는 실패가 발생 시 데이터를 재구성하여 다시 연산 할 수 있도록 한다.
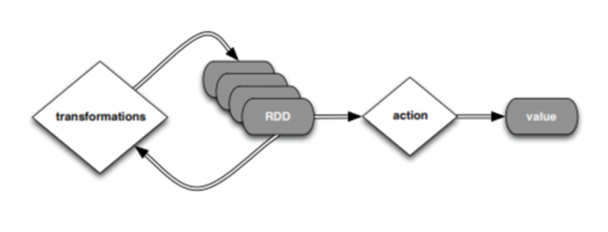
RDD 연산에서는 Action연산과 Transformation연산이라는 2가지 연산이 존재한다.
먼저 Transformation 연산은 RDD의 불변성과도 연관이 있는데, 스파크에서는 실제 데이터를 처리/연산 할 때 데이터를 바로 메모리에 올리지 않고 RDD 객채로 생성하여 연산의 수행과정만을 기록하는데 이때 수행되는 연산이 transformation 연산이다. 즉, 데이터를 실제로 수행하지 않고 데이터를 변형, 처리하는 과정을 RDD 객체로써 기록만 하는 것이다.

추가로 Transformation 연산은 Narrow Transformations(좁은 트랜스포메이션), Wide Transformations(넓은 프랜스포메이션) 이 있는데 Transformation 연산 수행 시, 하나의 연산이 수행될 데이터가 하나의 노드에 바로 있어서 수행되는 것이 Narrow Transformation이고, Wide Transformation은 연산처리되어야 할 데이터 클러스터 노드 여기저기에 분산되어 있어서 연산처리 수행 시, 메모리 간의 전달량이 많아 지는 것을 말한다. 즉, 네트워크 연산 처리량이 많아진다.

RDD 연산 중 Action 연산은 Transformation 연산으로 RDD 객체로 처리 기록이 끝난 뒤에 실제로 Action 연산을 통해 메모리에 데이터를 올려 수행하는 연산이다.
Transformation은 RDD 객채는 연산의 과정을 기록만하고 실제로 데이터가 메모리에 올라와 처리되는 것은 Action 연산을 수행할 때이다.
스파크 1.x대 에서는 RDD를 직접 개발하는 과정이 주로 였지만, 2.x로 업그레이드 되고나서는 우리가 익숙한 엑셀/ R / Python의 DataFrame과 같은 DataFrame이라는 구조적 데이터 형태를 사용하게 된다.


'BigData > Spark' 카테고리의 다른 글
| Spark DataFrame01 (Pyspark) (0) | 2020.04.11 |
|---|---|
| Spark RDD 문법 (0) | 2020.04.06 |
| Apache Spark란? (0) | 2020.04.04 |
| Apache Spark 3.0 (0) | 2020.03.06 |
| Pandas API on Apache Spark (0) | 2020.02.23 |



