
Notice
Recent Posts
Recent Comments
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- 연합학습
- TensorFlow
- 그래프
- 그래프 질의언어
- 분산 병렬 처리
- SQL
- graph database
- RStudio
- Neo4j
- 그래프 데이터베이스
- 그래프 에코시스템
- GSQL
- Cypher
- DeepLearning
- 인공지능
- 딥러닝
- Graph Tech
- GraphX
- r
- Python
- 빅데이터
- SparkML
- GDB
- Graph Ecosystem
- TigerGraph
- Federated Learning
- RDD
- BigData
- spark
- graph
Archives
- Today
- Total
Hee'World
Spark DataFrame01 (Pyspark) 본문
Spark에서 Row와 Column의 형태로 RDD를 표현하여 처리 할 수 있음 타입
- Python의 Pandas 패키지의 DataFrame과 R의 DataFrame과 동일한 개념
- Spark 2.x에서 Catalyst Optimizer의 도입으로 인해 Spark에서 지원하는 프로그래밍 타입 별 처리 성능이 동일하게 향상되었음

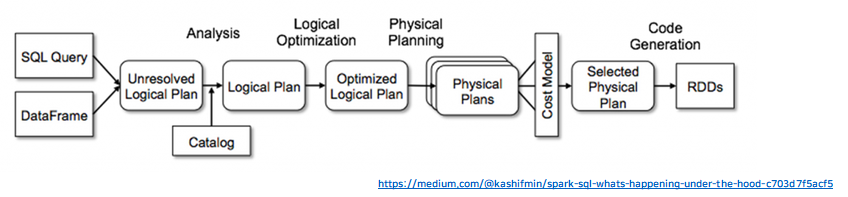

Spark DataFrame¶
- spark.read.csv()
- spark.read.json()
- spark.read.format("csv")
- spark.read.format("json")
- file://
- hdfs://
- hbase://
- s3://
In [1]:
stock = spark.read.csv("data/appl_stock.csv", inferSchema=True, header = True)
In [2]:
stock.printSchema()
In [4]:
stock.columns
Out[4]:
In [6]:
stock.describe().show()
In [7]:
stock.summary().show()
pandas Dataframe -> spark Datafrmae¶
In [9]:
import pandas as pd
In [10]:
pdf = pd.DataFrame({
'x': [[1,2,3], [4,5,6]],
'y': [['a','b','c'], ['d','e','f']]
})
In [11]:
pdf
Out[11]:
In [12]:
sdf = spark.createDataFrame(pdf)
In [13]:
sdf.show()
RDD -> Dataframe¶
In [16]:
from pyspark.sql import Row
In [17]:
rdd = spark.sparkContext.parallelize([
Row(x=[1,2,3], y=['a','b','c']),
Row(x=[4,5,6], y=['d','e','f'])
])
In [18]:
rdf = spark.createDataFrame(rdd)
In [19]:
rdf.show()
json -> Dataframe¶
In [20]:
jdf = spark.read.json("data/people.json")
In [21]:
jdf.show()
DataFrame Schema 설정¶
In [24]:
from pyspark.sql.types import StructField, IntegerType, StringType, StringType, StructType
In [23]:
data_schema = [StructField('age', IntegerType(), True), \
StructField('name', StringType(), True)]
In [25]:
struct_schema = StructType(fields=data_schema)
In [26]:
jdf = spark.read.json("data/people.json", schema=struct_schema)
In [27]:
jdf.show()
In [28]:
jdf.printSchema()
In [ ]:
'BigData > Spark' 카테고리의 다른 글
| Spark DataFrame 03 (Pyspark) (0) | 2020.04.11 |
|---|---|
| Spark DataFrame 02 (Pyspark) (0) | 2020.04.11 |
| Spark RDD 문법 (0) | 2020.04.06 |
| Spark RDD (0) | 2020.04.04 |
| Apache Spark란? (0) | 2020.04.04 |
'BigData/Spark' Related Articles
more


Comments