| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Federated Learning
- graph database
- 인공지능
- graph
- 딥러닝
- 그래프 에코시스템
- RStudio
- r
- Graph Ecosystem
- SparkML
- GraphX
- 빅데이터
- DeepLearning
- BigData
- 연합학습
- 분산 병렬 처리
- GDB
- GSQL
- 그래프 데이터베이스
- RDD
- 그래프 질의언어
- Python
- spark
- SQL
- TigerGraph
- 그래프
- TensorFlow
- Cypher
- Graph Tech
- Neo4j
- Today
- Total
Hee'World
[1004jonghee]Sharding & ReplicaSet 구성(4대의 머신) 본문
먼저 저는 4대의 머신으로 샤딩과 리플리카셋을 구성하였습니다.
1번 노드는 Shard01&ReplicaSet(Primary, secondary, arbiter), config server 01, mongos
2번 노드는 Shard02, config server 02
3번 노드는 Shard03&ReplicaSet(Primary, secondary, arbiter), config server 03
4번 노드는 Shard04&ReplicaSet(Primary, secondary, arbiter)
샤딩과 리플리카셋을 같은 머신에서 port 번호만 다르게 주어서 구성하였습니다.
꼭 같은 머신에서 할 필요는 없으며 머신의 수가 많다면 샤딩과 리플리카셋 구성을 물리적으로 다른 머신에 구성하셔도 됩니다.
대신, 샤딩되는 데이터를 복제해야 함으로 샤딩서버와 리플리카셋의 primary 서버는 같은 곳으로 하셔야 합니다.
예를 들면, 1번 머신은 shard server == ReplicaSet (Primary server) 이렇게 구성이 되고,
2번 머신은 ReplicaSet (secondary server)
3번 머신은 ReplicaSet(arbiter server)
이렇게 구성이 되어지면 1번 머신에서 샤드되어진 데이터가 1번 머신과 2번 머신에 한번 더 복제가 되어 지고, 1번머신이 장애가 발생하게 되면 3번 머신의 아비터 서버가 세컨더리서버 중 우선순위가 높은 서버를 primary서버로 결정을 해줍니다. 그러면 2번 머신은 primary 서버가 되어지고, 1번 머신을 복구하게 되면 세컨더리 서버로서 역활이 바뀌어 집니다.
샤드 서버와 리플리카셋을 구성하기 전에 물리적으로 저장될 폴더를 생성하여 줍니다. mongodb를 압축 푼 폴더에 생성합니다.

사진에서는 1번 서버의 폴더만 보여져 있습니다. 나머지 서버에는 구성한거와 똑같이 폴더를 생성하여 줍니다.
1번 서버는 shard01, config01, secondary, arbit
2번 서버의 폴더명은 shard02, config02
3번 서버는 shard03, config03, secondary, arbit
4번 서버는 shard04, secondary, arbit
이런식으로 폴더를 생성하여 줍니다.
폴더를 생성하셨으면, 몽고 인스턴스를 활성화합니다.
cmd창을 열고 mongodb 폴더 밑 bin 폴더로 이동합니다.
cd c:\mongodb\bin
이동하셨으면 샤딩과 리플리카셋을 활성화합니다.
샤딩과 리플리카셋을 동시에 올리는 명령어는
mongod --shardsvr --dbpath c:\mongodb\shard01 --port 40001 --replSet jeon --oplogSize 10 --rest
--shardsvr : 샤드서버라는 것을 지정합니다.
--dbpath : 데이터가 물리적으로 저장될 경로입니다.
--port : 40001번 포트를 사용하였습니다.
--replSet : 리플리카셋을 이름을 지정 합니다.
--oplogSize : oplog 의 Size를 10으로 지정합니다.
--rest : 웹으로도 상태를 확인 가능합니다.

1번 서버에서 정상적으로 인스턴스를 활성화 하셨다면
2번 서버에서는 샤딩서버만 활성화 합니다.
mongod --shardsvr --dbpath c:\mongodb\shard02 --port 40002
3번 서버에서는 샤딩서버와 리플리카셋 서버를 동시에 활성화합니다.
mongod --shardsvr --dbpath c:\mongodb\shard03 --port 40003 --replSet jeon2 --oplogSize 10 --rest
4번 서버에서는 샤딩서버와 리플리카셋 서버를 동시에 활성화합니다.
mongod --shardsvr --dbpath c:\mongodb\shard04 --port 40004 --replSet jeon3 --oplogSize 10 --rest
각 서버별샤드 및 리플리카셋 포트를 정리하면 1번 서버 : 40001
2번 서버 : 40002
3번 서버 : 40003
4번 서버 : 40004 이렇게 구성되었습니다.
그리고 --replSet 을 보시면 1번 서버는 jeon, 2번 서버는 jeon2, 3번 서버는 jeon3 이렇게 입력하였는데
이유는 리플리카셋을 구성할때 jeon의 secondary와 arbit
jeon2의 secondary와 arbit
jeon3의 secondary와 arbit를 구성할 것입니다
즉, 여기서 각 repliSet의 Primary서버가 될것이기 때문에 이름도 다르게 준 것입니다.
이렇게 샤드서버와 리플리카셋을 활성화 정상적으로 활성화 하셨다면 Config Server를 활성화 하셔야 합니다.
새로운 cmd창을 열고 c:\mongodb\bin 폴더로 이동합니다.

config server는 1,2,3번 서버에 활성화 합니다.
1번 서버 mongod --configsvr --dbpath c:\mongodb\config01 --port 50001
2번 서버 mongod --configsvr --dbpath c:\mongodb\config02 --port 50002
3번 서버 mongod --configsvr --dbpath c:\mongodb\config03 --port 50003
--configsvr : configserver를 지정합니다.
--dbpath : configserver 데이터를 저장할 물리적 경로입니다.
--port : config 서버의 포트번호입니다.
이렇게 샤드서버&리플리카셋 인스턴스화 configserver 인스턴스를 활성화하였습니다.
그럼 다음으로 mongos 프로세스에 configserver를 등록하여 줍니다.
새로운 cmd창을 열고 c:\mongodb\bin폴더로 이동합니다.

mongos 프로세스는 1번 서버에서 활성화하였습니다.
mongos 프로세스를 활성화 하고 configserver를 활성화하는 명령어 입니다.
mongos --configdb 1번서버의 IP:50001(1번 서버 configserver의 포트번호),2번서버의 IP:50002(2번 서버에 있는 configserver 포트번호),3번 서버의 IP:50003(3번서버에 있는 configserver 포트번호) --port 50000 (mongos 포트번호) --chunkSize 1
--->
mongos --configdb 192.168.1.1:50001,192.168.1.2:50002,192.168.1.3:50003 --port 50000 --chunkSize 1
--chunkSize : 샤딩될때 분활 되는 크기 입니다.
mongos 프로세스를 활성화 하셨다면 mongos에 접속하여 샤드서버를 등록합니다.
새로운 cmd창을 열고 cd c:\mongodb\bin 폴더로 이동합니다.
1. mongo mongos 192.168.1.13(프로세스를 활성화한 서버의 IP):50000(mongos 프로세스의 포트번호)/admin(amdimDB로 접속합니다.)
2. 접속한 뒤에 db.runCommand({addshard : "192.168.1.13(1번shard서버의 IP):40001(1번 shard서버의 포트번호)"})
db.runCommand({addshard : "192.168.1.14(2번shard서버의 IP):40002(2번 shard서버의 포트번호)"})
db.runCommand({addshard : "192.168.1.15(3번shard서버의 IP):40003(3번 shard서버의 포트번호)"})
db.runCommand({addshard : "192.168.1.11(4번shard서버의 IP):40004(1번 shard서버의 포트번호)"})
이렇게 명령어를 입력하여 mongos 프로세스에 각 샤드서버를 등록합니다.

3. 그다음 testDB를 활성화 합니다.
db.runCommand({enablesharding : "test"}) 이렇게 입력합니다.
4. 여기서 현재 mongos에 접속한 cmd창을 끄지 말고 최소화 하거나 창을 작게 해서 한쪽에 둔뒤에 새로운 cmd창을 엽니다.
cd c:\mongodb\bin 폴더로 이동합니다.
여기서 replicaSet의 secondary 서버를 활성화 합니다.
secondary 서버는 1,3,4번 서버에 구성하였습니다.
명령어는
1번 서버는 mongod --dbpath c:\mongodb\secondary --port 10001 -replSet jeon --oplogSize 10 --rest
3번 서버는 mongod --dbpath c:\mongodb\secondary --port 10001 -replSet jeon2 --oplogSize 10 --rest
4번 서버는 mongod --dbpath c:\mongodb\secondary --port 10001 -replSet jeon3 --oplogSize 10 --rest
여기서 포트번호는 각 서버마다 동일하게 하였고 리플릴셋 네임만 다르게 주어서 인스턴스를 활성화 하였습니다.

5. 다음은 arbiter 서버를 활성화 합니다.
새로운 cmd창을 열고 cd c:\mongodb\bin 폴더로 이동합니다.
arbiter 서버의 명령어는
1번 서버는 mongod --dbpath c:\mongodb\arbit --port 10002 -replSet jeon --oplogSize 10 --rest
3번 서버는 mongod --dbpath c:\mongodb\arbit --port 10002 -replSet jeon2 --oplogSize 10 --rest
4번 서버는 mongod --dbpath c:\mongodb\arbit --port 10002 -replSet jeon3 --oplogSize 10 --rest
secondary 서버를 활성화하는 명령어와 동일하지만 물리적으로 데이터가 저장될 경로와 포트번호만 다르게 주었습니다.
6. 이번에는 Primary 서버에 secondary 서버와 arbiter 서버를 등록합니다. (1,3,4번 서버에 똑같이 등록합니다.)
새로운 cmd창을 열고 cd c:\mongodb\bin 폴더로 이동합니다.
Primary서버로 접속하는 명령어 입니다.
mongo 192.168.1.13(리플리카셋의 Primary Server):40001(Primary 서버의 포트번호)/admin(adminDB로 접속) 을 입력하니다
1번 서버 -> mongo 192.168.1.13:40001/admin
2번 서버 -> mongo 192.168.1.15:40003/admin
3번 서버 -> mondo 192.168.1.11:40004/admin
각각의 서버의 Primary 서버로 접속하여 secondary 서버와 arbiter 서버를 등록하고 리플리카셋을 구성합니다.
secondary 서버와 arbiter 서버를 등록하는 명령어는
1번 서버 db.runCommand({"replSetInitiate" : {"_id":"jeon(리플리카셋 네임)","members":[{"_id":1,"host":"192.168.1.13:40001"(제일 먼저 오는 곳이 Primary서버입니다)},{"_id":2,"host":"192.168.1.13:10001"(secondary 서버)},{"_id":3,"host":"192.168.1.13:10002",arbiterOnly:true(아비터 서버가 될곳에 이 명령어를 입력합니다.)}]}})
2번 서버 db.runCommand({"replSetInitiate" : {"_id":"jeon2","members":[{"_id":1,"host":"192.168.1.14:40001"},{"_id":2,"host":"192.168.1.14:10001"},{"_id":3,"host":"192.168.1.14:10002",arbiterOnly:true}]}})
3번 서버 db.runCommand({"replSetInitiate" : {"_id":"jeon3,"members":[{"_id":1,"host":"192.168.1.11:40001"},{"_id":2,"host":"192.168.1.11:10001"},{"_id":3,"host":"192.168.1.11:10002",arbiterOnly:true}]}})
이렇게 각 서버의 Primary서버로 접속을 하여 등록을 하여 구성합니다.

7. 리플리카셋 구성이 완료되면 잠시 창을 최소화 시켜놓았던 mongos 접속창으로 다시 되돌아 갑니다.
여기서 test DB로 전환하여 things collection 의 Index키를 등록하여 줍니다.
그리고 다시 admin DB로 전환하여 things의 Index키를 샤드키로 구성하여 줍니다.
명령어
-> use test
-> db.things.ensureIndex({empno : 1})
-> use admin
-> db.runCommand({shardcollection : "test.things", key : {empno : 1}})

8. 샤드가 잘 붙었는지 확인하고 임의의 데이터를 넣어봅니다.
샤드 리스트 확인
-> db.runCommand({listshards : 1}) (adminDB에서 사용하셔야 합니다)
그다음 testDB로 전환하고 임의 데이터 50만건정도 넣어 봅니다.
-> use test
-> for (var n=1;n<=500000;n++) db.things.save({empno : n, ename : "test"})

9. 데이터가 잘 분산 되었는지 확인 합니다.

10. 다음은 csv 파일 업로드 하는 방법입니다. (csv 파일 업로드하는 화면은 미쳐 캡쳐를 못했습니다 ㅠㅠ)
cmd 창을 하나 새로 열어서 cd c:\mongodb\bin 폴더로 이동합니다.
mongos 프로세스에 접속하여 testDB로 전환하고, air라는 collection에 적당한 인덱스값을 지정해 줍니다.
-> use test
-> db.air.ensureIndex({Month: 1})
-> use admin
-> db.runCommand({shardcollection : "test.air", key : {Month: 1}})
다음은 또 하나의 cmd창을 열거나 기본의 접속되어 있는 프로세스에서 exit 라고 치신뒤 빠져 나와서
다음의 명령어를 입력합니다.
명령어 ->
mongoimport -h 192.168.1.13:50000 -d test -c air 1987.csv -headerline -type csv
-h : 업로드할 host의 주소와 포트번호입니다.
-d : DB명 입니다.
-c : collection명 입니다.
1987.csv -> 업로드할 파일의 경로를 입력합니다. 기본적으로 bin폴더를 읽습니다.
-headerlin : 파일의 헤더부분을 읽겠다는 표시입니다.
호스트가 192.168.1.13:50000이며 testDB에 air라는 collection에 1987.csv 파일을 업로드 한다는 의미 입니다.
mongos 프로세스가 이 데이터를 받아서 각 샤드로 분산되어 저장되어 지며 주의사항이 있습니다.
업로드 하실때, mongos 프로세스에 업로드 한다는 점.
그리고 샤드는 인덱스를 이용하여 데이터를 분산하기 때문에 인덱스값을 잘 지정하셔야 합니다.
air라는 collection에 Month라는 필드를 인덱스 값으로 잡았다면 이 Month라는 필드는 값이 어느정도 분산되어 질 수 있는 값이여야 한다는 것입니다. 예를 들어, Month라는 필드가 1~1000000의 값으로 되어 있다면 너무 높은 카디날리티 값이며, 1~5정도 되는 값이면 너무 적은 카디날리티의 값이기 때문에 샤드가 느리거나 제대로 분산이 되지 않을 수가 있습니다. 그래서 파일을 업로드시에나 샤딩시 적당한 인덱스값을 지정해주셔 합니다.
--------------------------------------------------------------------------------------------------------------
제가 구성하여 본건 여기까지 입니다.
부족한게 많습니다. ㅠㅠㅠ
틀린 부분이 있거나 부족한 부분이 있으면 조언을 해주시면 감사하겠습니다 ㅠㅠ
'BigData > MongoDB' 카테고리의 다른 글
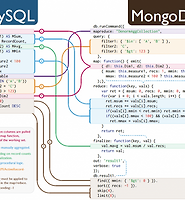
| MySQL Query를 MongoDB 쿼리로.... (0) | 2013.11.29 |
|---|---|
| MongoDB query & mySql query (0) | 2013.11.29 |
| MongoDB CRUD Intorduction (0) | 2013.09.12 |
| [1004jonghee]SQL to MongoDB Mapping (0) | 2013.08.29 |
| [1004jonghee]MongoDB 설치 (0) | 2013.07.08 |