| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- RStudio
- 인공지능
- Federated Learning
- spark
- 분산 병렬 처리
- 그래프 에코시스템
- SparkML
- r
- Graph Ecosystem
- TensorFlow
- 연합학습
- GraphX
- RDD
- DeepLearning
- BigData
- 그래프
- 빅데이터
- graph
- SQL
- GSQL
- graph database
- Python
- 그래프 데이터베이스
- TigerGraph
- 그래프 질의언어
- GDB
- 딥러닝
- Neo4j
- Graph Tech
- Cypher
- Today
- Total
Hee'World
[1004jonghee]HIVE 설치하기 본문
먼저 HIVE란?
Hive
하둡 기반의 데이터웨어하우징용 솔루션입니다. 페이스북에서 개발됐으며, 오픈 소스로 공개되며 주목을 받은 기술입니다. SQL과 매우 유사한 HiveQL이라는 쿼리를 제공합니다. 그래서 자바를 모르는 데이터 분석가들도 쉽게 하둡 데이터를 분석할 수 있게 도와줍니다. HiveQL은 내부적으로 MapReduce 잡으로 변환되어 실행됩니다. (공식 사이트: http://hive.apache.org)
이제 HIVE를 설치해보겠습니다.
먼저 HIVE를 다운로드 합니다. 홈페이지에서 다운 받으셔도 되고 wget 명령어를 이용하여 받으셔도 됩니다.
wget http://apache.mirror.cdnetworks.com/hive/hive-0.11.0.tar.gz

다운을 받으셨으면 다운 받은 압축 파일을 압축해제 합니다.

압축을 해제 하셨으면 디렉토리(폴더)를 원하는 경로에 이동합니다.
저는 mv hive-0.11.0 /usr/local/hive 이렇게 명령어를 쳐서 이동하였습니다.
이제 이동한 HIVE 폴더의 conf폴더로 이동하여 hive-env.template파일을 설정하겠습니다.

vi 편집기를 이용하여 파일은 열어 HADOOP_HOME을 적어줍니다. HIVE가 하둡에 접속하려면 하둡의 설치 디렉토리를 알고 있어야 합니다.

환경설정이 끝났다면 이제 HIVE를 실행합니다.
hive디렉토리 아래에 bin디렉토리에 있는 hive파일은 실행합니다.
실행하고 나서 hive> 이렇게 나오신다면 설치 성공하신것 입니다.

'BigData > Hive' 카테고리의 다른 글
| [1004jonghee] HIVE 사용하기 (apache.org)문서 (0) | 2013.08.19 |
|---|---|
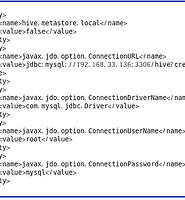
| [1004jonghee]Hive 메타스토어(MySQL) 구축 (0) | 2013.07.18 |
| [1004jonghee]HIVE 외부 데이터 업로드 하여 SELECT 하기 (0) | 2013.07.12 |