
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- graph
- 분산 병렬 처리
- DeepLearning
- 인공지능
- Graph Tech
- TensorFlow
- 그래프 에코시스템
- Neo4j
- 그래프
- r
- 그래프 데이터베이스
- BigData
- 그래프 질의언어
- Federated Learning
- GDB
- Cypher
- GSQL
- RDD
- graph database
- GraphX
- 딥러닝
- RStudio
- Graph Ecosystem
- Python
- spark
- SparkML
- SQL
- TigerGraph
- 빅데이터
- 연합학습
- Today
- Total
Hee'World
Cypher 기초(2/2) 본문
Cypher 키워드
기타 프로그래밍 언어나 SQL과 유사하게 Cypher에도 질의를 위한 기본적인 문법이 있음
■ MATCH
- Cypher의 MATCH키워드는 데이터베이스에서 기존 노드, 관계, 레이블, 속성 또는 패턴을 검색하는 것
- SQL에 익숙하다면 SELECT와 MATCH가 거의 비슷하게 작동
- MATCH는 데이터베이스에서 모든 노드 레이블을 찾고, 특정 노드를 검색하고, 특정 관계가 있는 모든 노드를 찾고, 노드 및 관계의 패턴을고 찾는 등 을 사용하여 훨씬 더 많은 작업을 수행할 수 있음
■ RETURN
- Cypher의 RETURN키워드는 Cypher 쿼리에서 반환할 수 있는 값 또는 결과를 지정
- 쿼리 결과에서 노드, 관계, 노드 및 관계 속성 또는 패턴을 반환하도록 Cypher에 지시할 수 있고 데이터 저장을 수행할 때는 필요하지 않지만 읽기에는 필요함
- 노드 및 관계 변수는 RETURN을 사용할 때 중요함 노드, 관계, 속성 또는 패턴을 다시 가져오려면 반환하려는 데이터에 대해 MATCH절에 변수를 지정해야 함
예제 1
그래프에서 Person 레이블이 지정된 노드를 찾고, RETURN절 에서 Person노드를 검색하려면 노드에 대해 p와 같은 변수를 사용함
MATCH (p:Person)
RETURN p
LIMIT 1예제 2
그래프에서 Person 이름이 'Tom Hanks'인 노드를 찾고 나중에 같은 이름을 참조하는 한 변수 이름을 원하는 대로 지정할 수 있음
MATCH (tom:Person {name: 'Tom Hanks'})
RETURN tom예제 3
Tom Hanks가 감독한 `Movie`를 찾기
MATCH (:Person {name: 'Tom Hanks'})-[:DIRECTED]->(movie:Movie)
RETURN movie예제 4
Tom Hanks가 감독한 것을 찾지만 이번에는 영화 제목만 반환
MATCH (:Person {name: 'Tom Hanks'})-[:DIRECTED]->(movie:Movie)
RETURN movie.title
SQL과 마찬가지로 AS키워드를 사용하고 속성에 더 간편한 이름으로 별칭을 지정하여 결과의 변수명을 바꿀 수 있음
고객의 주문과 주문의 항목 수를 나열하기 위한 예제
//cleaner printed results with aliasing
MATCH (tom:Person {name:'Tom Hanks'})-[rel:DIRECTED]-(movie:Movie)
RETURN tom.name AS name, tom.born AS `Year Born`, movie.title AS title, movie.released AS `Year Released`■ Cypher 데이터 생성
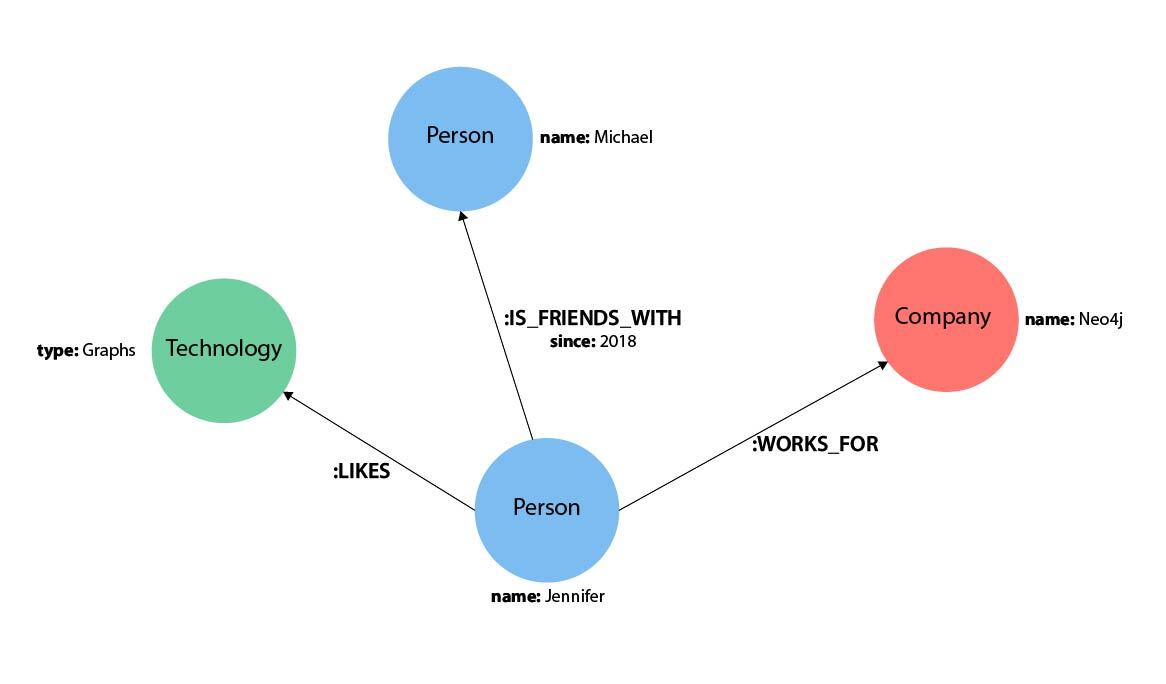
위와 같은 그래프가 존재할 때 Person 레이블에 name이 'Mark'인 노드를 생성하고 결과를 반환
CREATE (friend:Person {name: 'Mark'})
RETURN friend결과
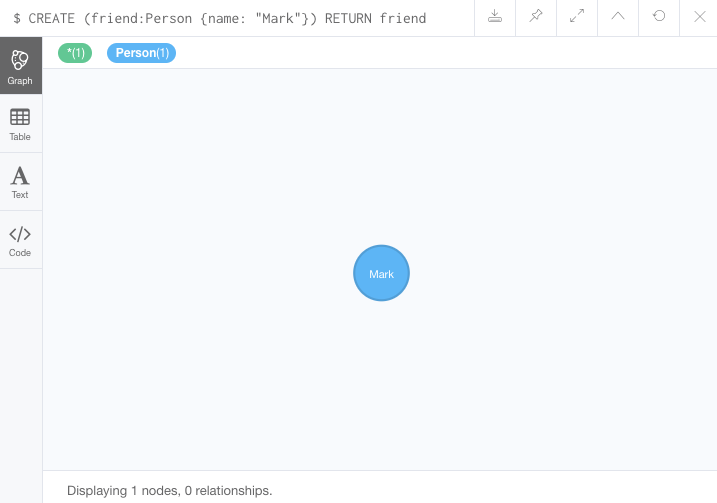
Person 레이블 중 'Jennifer'와 'Mark'의 관계를 생성
MATCH (jennifer:Person {name: 'Jennifer'})
MATCH (mark:Person {name: 'Mark'})
CREATE (jennifer)-[rel:IS_FRIENDS_WITH]->(mark)결과
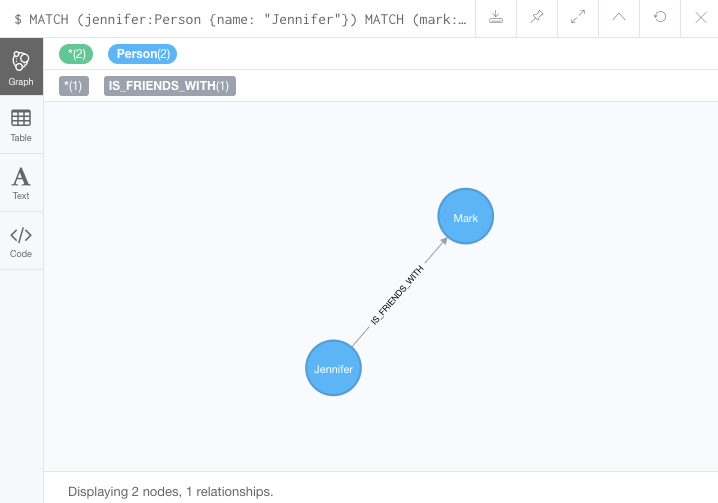
■ Cypher 데이터 수정
'Jennifer'의 속성값인 birthdate를 '1980-01-01'로 수정
MATCH (p:Person {name: 'Jennifer'})
SET p.birthdate = date('1980-01-01')
RETURN p결과
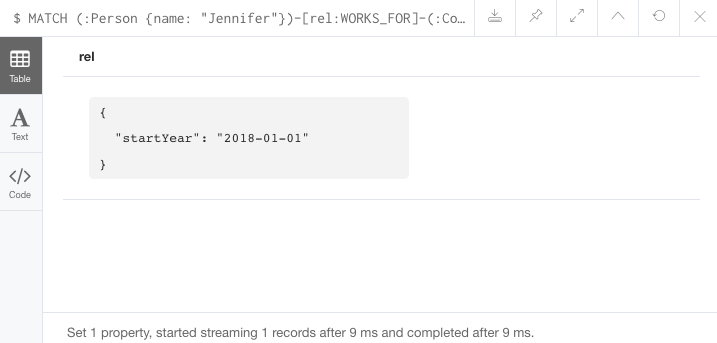
MATCH (:Person {name: 'Jennifer'})-[rel:WORKS_FOR]-(:Company {name: 'Neo4j'})
SET rel.startYear = date({year: 2018})
RETURN rel결과
■ Cypher 데이터 삭제
위에서 생성했던 'Jennifer'와 'Mark'의 관계를 삭제
MATCH (j:Person {name: 'Jennifer'})-[r:IS_FRIENDS_WITH]->(m:Person {name: 'Mark'})
DELETE r결과

■ 노드 삭제
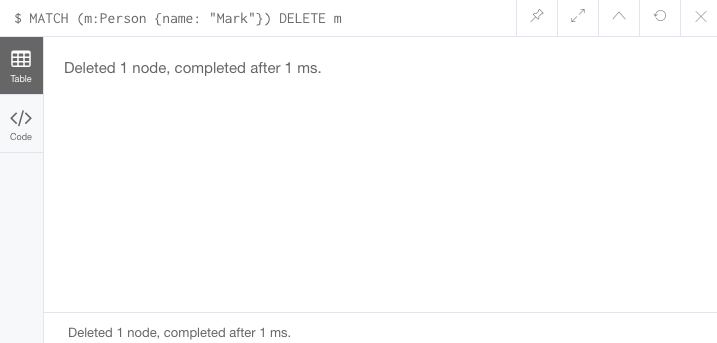
위에서 생성한 'Mark' 노드를 삭제
MATCH (m:Person {name: 'Mark'})
DELETE m결과
■ 노드 및 연결된 관계 삭제
MATCH (m:Person {name: 'Mark'})
DETACH DELETE m
■ 속성 삭제
//delete property using REMOVE keyword
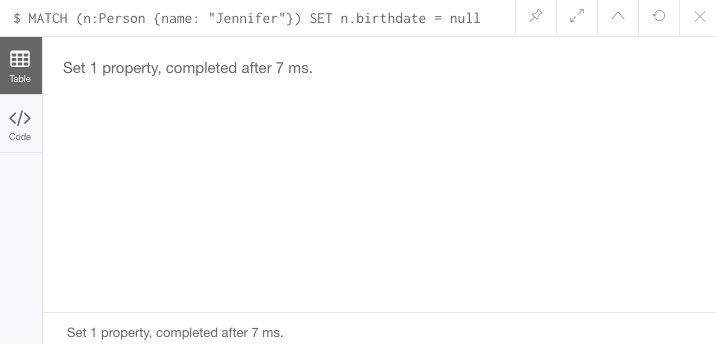
MATCH (n:Person {name: 'Jennifer'})
REMOVE n.birthdate
//delete property with SET to null value
MATCH (n:Person {name: 'Jennifer'})
SET n.birthdate = null결과
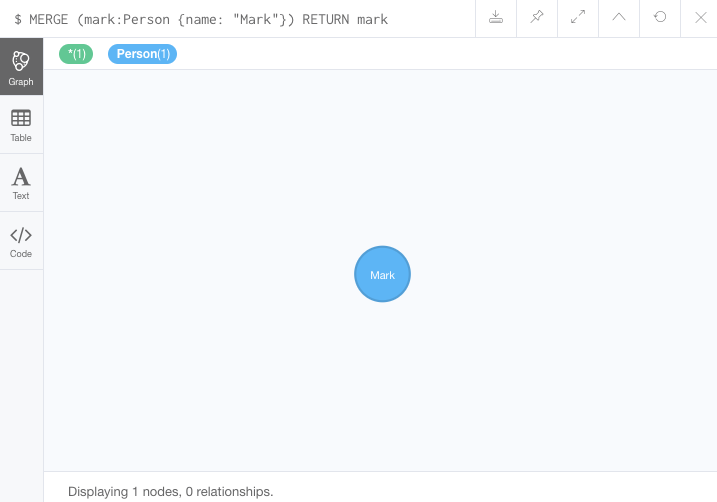
■ MERGE
MERGE (mark:Person {name: 'Mark'})
RETURN mark결과
MATCH (j:Person {name: 'Jennifer'})
MATCH (m:Person {name: 'Mark'})
MERGE (j)-[r:IS_FRIENDS_WITH]->(m)
RETURN j, r, m결과
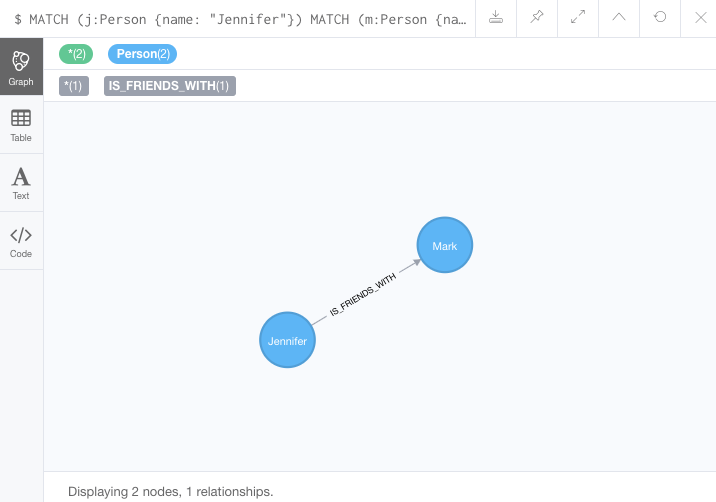
MERGE (m:Person {name: 'Mark'})-[r:IS_FRIENDS_WITH]-(j:Person {name:'Jennifer'})
ON CREATE SET r.since = date('2018-03-01')
ON MATCH SET r.updated = date()
RETURN m, r, j
■ WHERE 절
//query using equality check in the MATCH clause
MATCH (j:Person {name: 'Jennifer'})
RETURN j;
//query using equality check in the WHERE clause
MATCH (j:Person)
WHERE j.name = 'Jennifer'
RETURN j;//query using inequality check in the WHERE clause
MATCH (j:Person)
WHERE NOT j.name = 'Jennifer'
RETURN jRanges
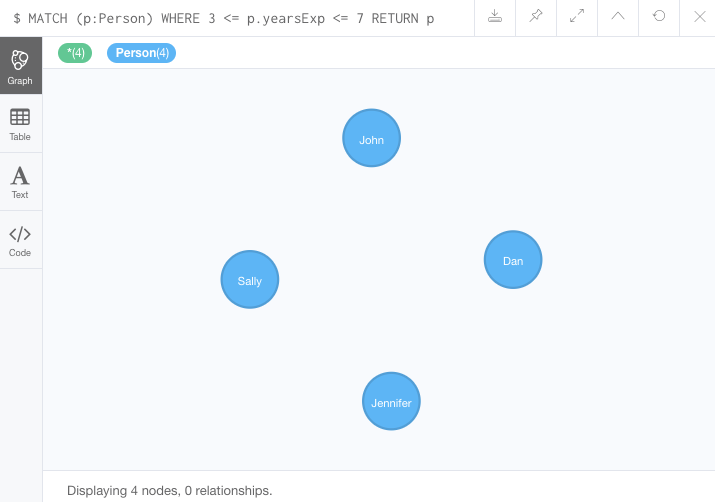
MATCH (p:Person)
WHERE 3 <= p.yearsExp <= 7
RETURN p결과
■ Testing if a Property Exists
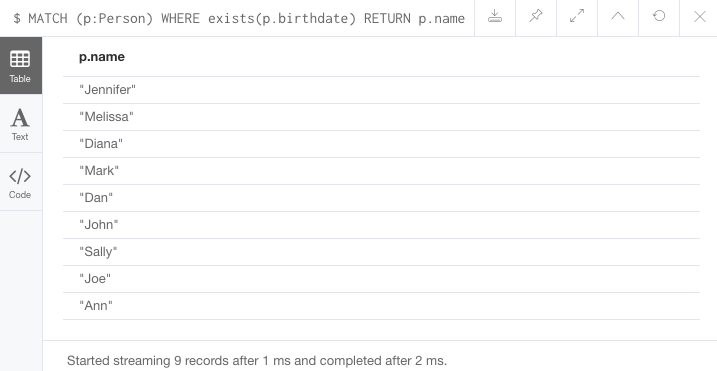
//Query1: find all users who have a birthdate property
MATCH (p:Person)
WHERE exists(p.birthdate)
RETURN p.name;
//Query2: find all WORKS_FOR relationships that have a startYear property
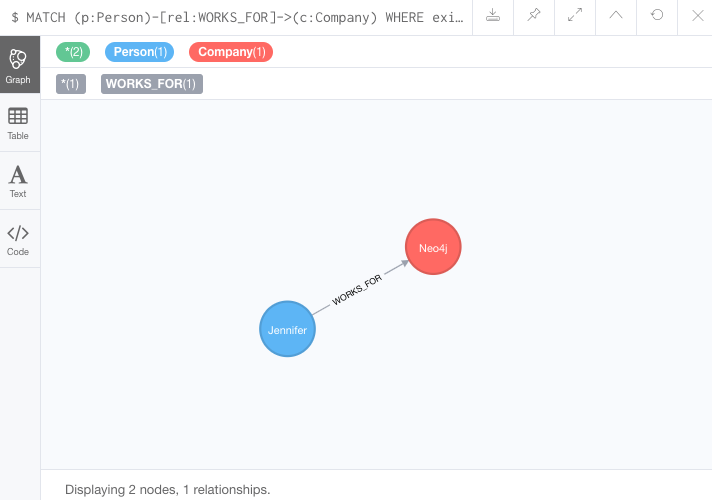
MATCH (p:Person)-[rel:WORKS_FOR]->(c:Company)
WHERE exists(rel.startYear)
RETURN p, rel, c;결과 1
결과 2
■ Checking Strings - Partial Values, Fuzzy Searches, and More
//check if a property starts with 'M'
MATCH (p:Person)
WHERE p.name STARTS WITH 'M'
RETURN p.name;
//check if a property contains 'a'
MATCH (p:Person)
WHERE p.name CONTAINS 'a'
RETURN p.name;
//check if a property ends with 'n'
MATCH (p:Person)
WHERE p.name ENDS WITH 'n'
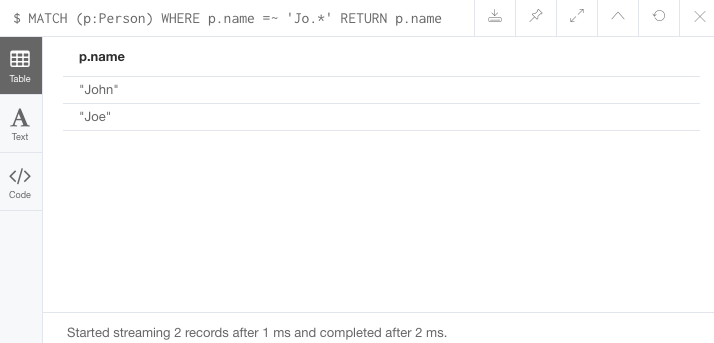
RETURN p.name;MATCH (p:Person)
WHERE p.name =~ 'Jo.*'
RETURN p.name결과
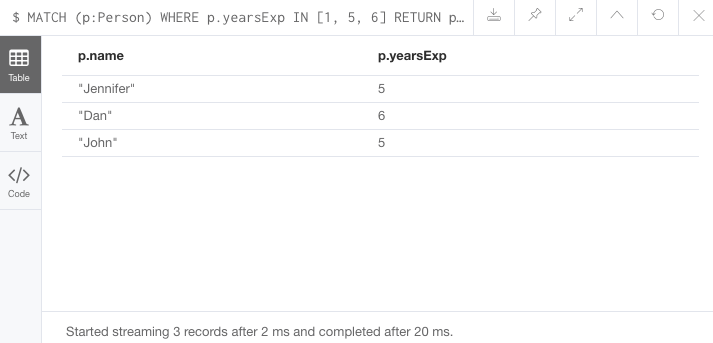
MATCH (p:Person)
WHERE p.yearsExp IN [1, 5, 6]
RETURN p.name, p.yearsExp결과
■ Filtering on Patterns
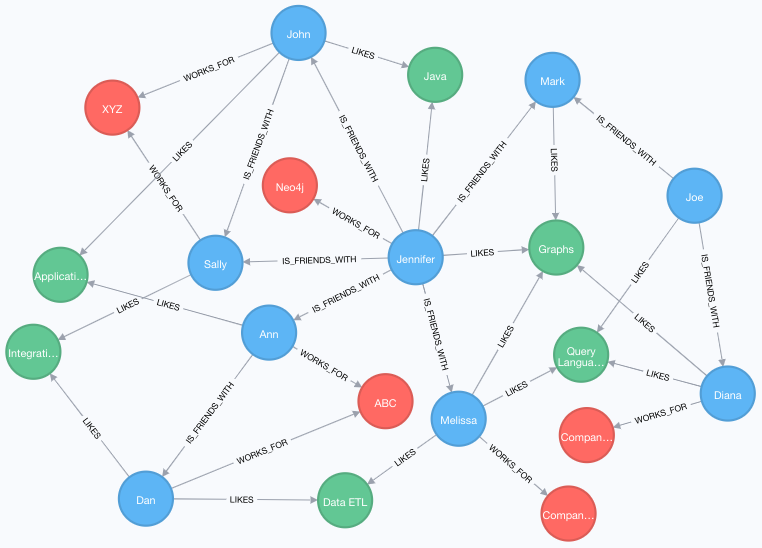
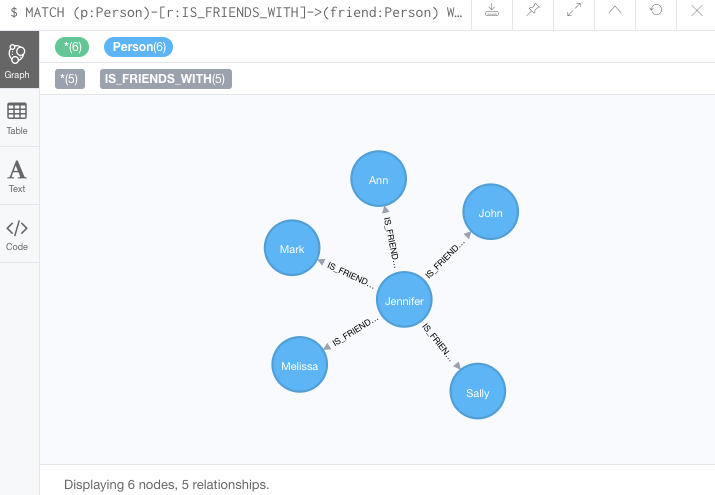
//Query1: find which people are friends of someone who works for Neo4j
MATCH (p:Person)-[r:IS_FRIENDS_WITH]->(friend:Person)
WHERE exists((p)-[:WORKS_FOR]->(:Company {name: 'Neo4j'}))
RETURN p, r, friend;
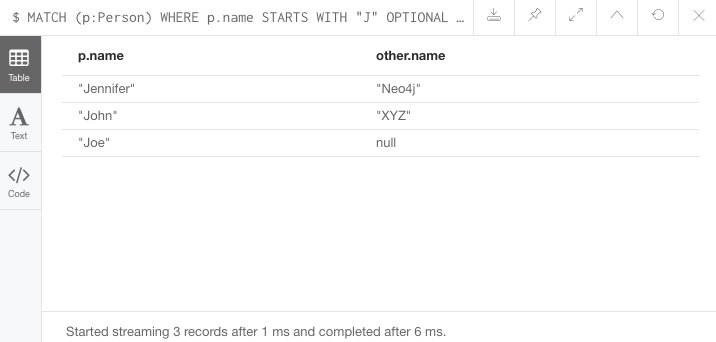
//Query2: find Jennifer's friends who do not work for a company
MATCH (p:Person)-[r:IS_FRIENDS_WITH]->(friend:Person)
WHERE p.name = 'Jennifer'
AND NOT exists((friend)-[:WORKS_FOR]->(:Company))
RETURN friend.name;결과 1
결과 2
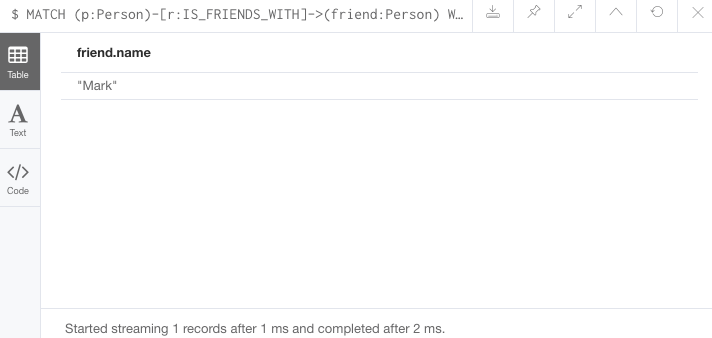
■ Optional Patterns
//find all people whose name starts with J and who may work for a company.
MATCH (p:Person)
WHERE p.name STARTS WITH 'J'
OPTIONAL MATCH (p)-[:WORKS_FOR]-(other:Company)
RETURN p.name, other.name;결과
■ Controlling Query Processing
Aggregation in Cypher
- Cypher에서는 그룹화 키를 지정할 필요가 없으며 반환 절에서 집계되지 않은 필드를 기준으로 암시적으로 그룹화됨
- 다른 질의 언어의 구문보다 훨씬 간결하게 사용할 수 있음
//Query1: see the list of Twitter handle values for Person nodes
MATCH (p:Person)
RETURN p.twitter;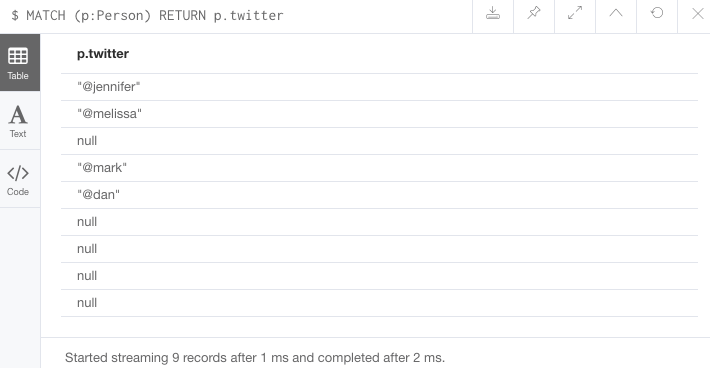
//Query2: count of the non-null `twitter` property of the Person nodes
MATCH (p:Person)
RETURN count(p.twitter);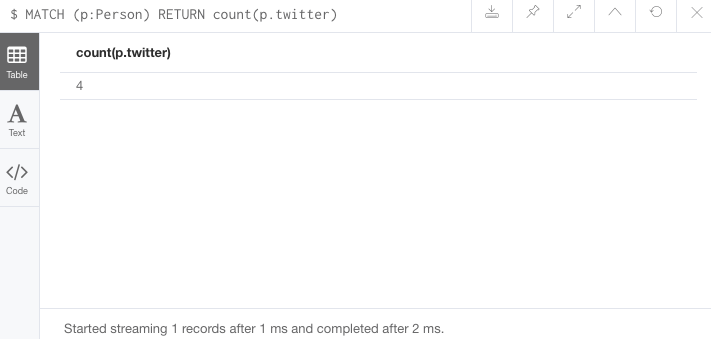
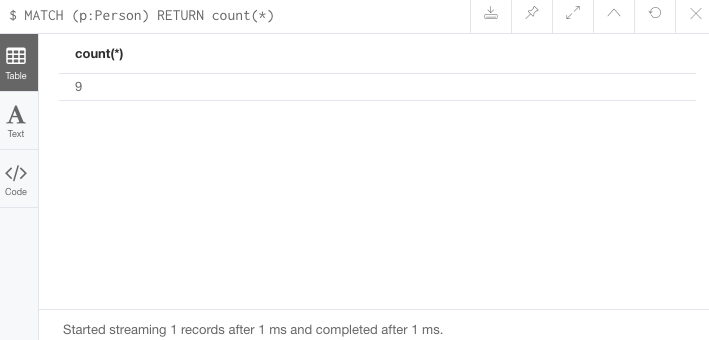
//Query3: count on the Person nodes
MATCH (p:Person)
RETURN count(*);
Aggregating Values
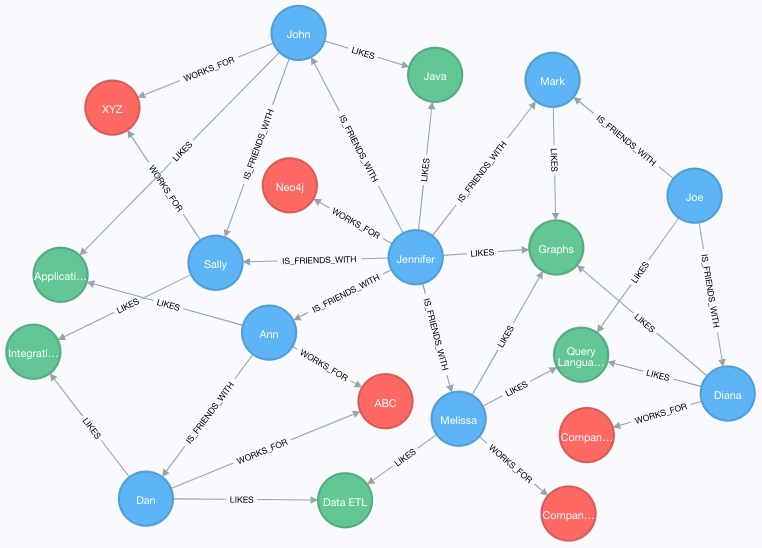
MATCH (p:Person)-[:IS_FRIENDS_WITH]->(friend:Person)
RETURN p.name, collect(friend.name) AS friend
Counting Values in a List
//Query5: find number of items in collected list
MATCH (p:Person)-[:IS_FRIENDS_WITH]->(friend:Person)
RETURN p.name, size(collect(friend.name)) AS numberOfFriends;
//Query6: find number of friends who have other friends
MATCH (p:Person)-[:IS_FRIENDS_WITH]->(friend:Person)
WHERE size((friend)-[:IS_FRIENDS_WITH]-(:Person)) > 1
RETURN p.name, collect(friend.name) AS friends, size((friend)-[:IS_FRIENDS_WITH]-(:Person)) AS numberOfFoFs;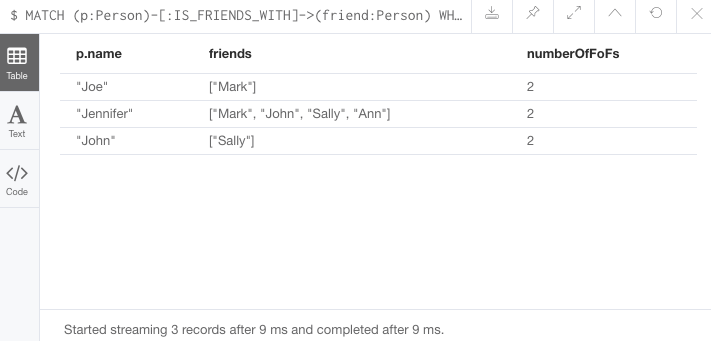
Manipulating Results and Output
Chaining Queries Together
WITH절은 쿼리의 결과를 다른 쿼리의 값을 전달하며 사용할 쿼리 내에서 일부 중간 계산 또는 작업을 실행할 수 있음
사용하려는 WITH절에 변수를 지정해야 하며 해당 변수만 쿼리의 다음 부분으로 전달됨
이 기능을 사용하는 방법에는 여러 가지가 있음(예: 계산, 수집, 필터링, 결과 제한)
//Query7: find and list the technologies people like
MATCH (a:Person)-[r:LIKES]-(t:Technology)
WITH a.name AS name, collect(t.type) AS technologies
RETURN name, technologies;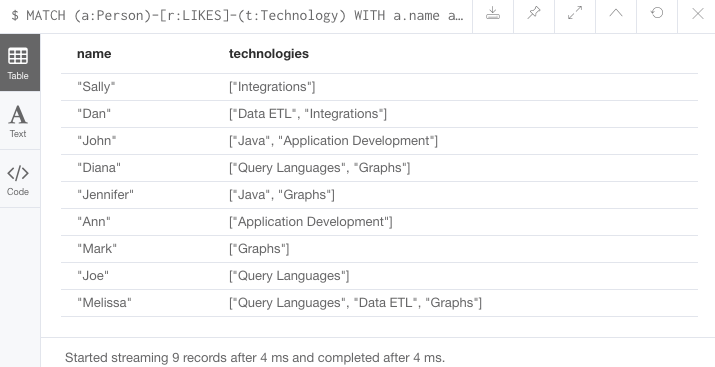
//Query8: find number of friends who have other friends - cleaner Query6
MATCH (p:Person)-[:IS_FRIENDS_WITH]->(friend:Person)
WITH p, collect(friend.name) AS friendsList, size((friend)-[:IS_FRIENDS_WITH]-(:Person)) AS numberOfFoFs
WHERE numberOfFoFs > 1
RETURN p.name, friendsList, numberOfFoFs;
//find people with 2-6 years of experience
WITH 2 AS experienceMin, 6 AS experienceMax
MATCH (p:Person)
WHERE experienceMin <= p.yrsExperience <= experienceMax
RETURN p
Looping through List Values
값을 검사하거나 분리하려는 목록이 있는 경우 UNWIND절을 사용할 수 있으며 이것은 collect() 함수의 반대 작업을 수행 하고 목록을 별도의 행에 있는 개별 값으로 분리함
//Query9: for a list of techRequirements, look for people who have each skill
WITH ['Graphs','Query Languages'] AS techRequirements
UNWIND techRequirements AS technology
MATCH (p:Person)-[r:LIKES]-(t:Technology {type: technology})
RETURN t.type, collect(p.name) AS potentialCandidates;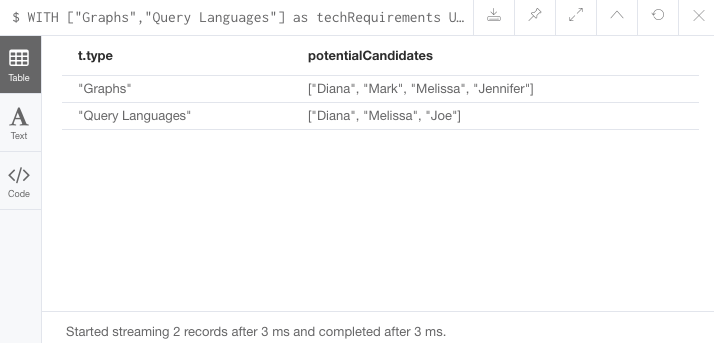
Ordering Results
//Query11: for a list of techRequirements, look for people who have each skill - ordered Query9
WITH ['Graphs','Query Languages'] AS techRequirements
UNWIND techRequirements AS technology
MATCH (p:Person)-[r:LIKES]-(t:Technology {type: technology})
WITH t.type AS technology, p.name AS personName
ORDER BY technology, personName
RETURN technology, collect(personName) AS potentialCandidates;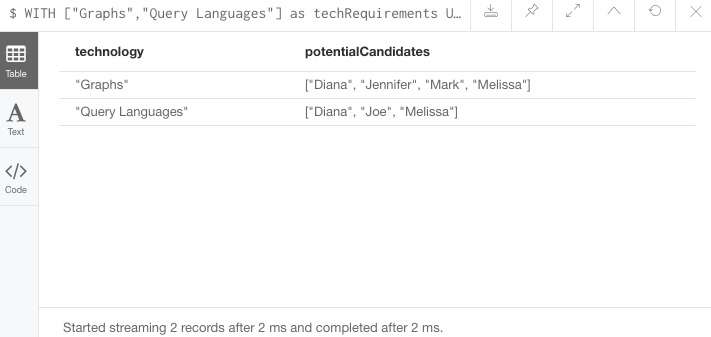
Returning Unique Results
//Query13: find people who have a twitter or like graphs or query languages
MATCH (user:Person)
WHERE user.twitter IS NOT null
WITH user
MATCH (user)-[:LIKES]-(t:Technology)
WHERE t.type IN ['Graphs','Query Languages']
RETURN DISTINCT user.name
Limiting Number of Results
//Query14: find the top 3 people who have the most friends
MATCH (p:Person)-[r:IS_FRIENDS_WITH]-(other:Person)
RETURN p.name, count(other.name) AS numberOfFriends
ORDER BY numberOfFriends DESC
LIMIT 3결과

Dates, datetimes, and durations
UNWIND [
{ title: "Cypher Basics I",
created: datetime("2019-06-01T18:40:32.142+0100"),
datePublished: date("2019-06-01"),
readingTime: {minutes: 2, seconds: 15} },
{ title: "Cypher Basics II",
created: datetime("2019-06-02T10:23:32.122+0100"),
datePublished: date("2019-06-02"),
readingTime: {minutes: 2, seconds: 30} },
{ title: "Dates, Datetimes, and Durations in Neo4j",
created: datetime(),
datePublished: date(),
readingTime: {minutes: 3, seconds: 30} }
] AS articleProperties
CREATE (article:Article {title: articleProperties.title})
SET article.created = articleProperties.created,
article.datePublished = articleProperties.datePublished,
article.readingTime = duration(articleProperties.readingTime)- created속성은 쿼리 DateTime가 실행되는 시점의 datetime형과 같은 유형
- date속성은 쿼리 Date가 실행된 날짜와 동일한 유형
- readingTime.Duration속성은 3분 30초 유형
MATCH (article:Article {title: "Dates, Datetimes, and Durations in Neo4j"})
SET article.datePublished = date("2019-09-30")WITH apoc.date.parse("Sun, 29 September 2019", "ms", "EEE, dd MMMM yyyy") AS ms
MATCH (article:Article {title: "Dates, Datetimes, and Durations in Neo4j"})
SET article.datePublished = date(datetime({epochmillis: ms}))MATCH (article:Article {title: "Dates, Datetimes, and Durations in Neo4j"})
SET article.readingTime = article.readingTime + duration({minutes: 1})
Subqueries
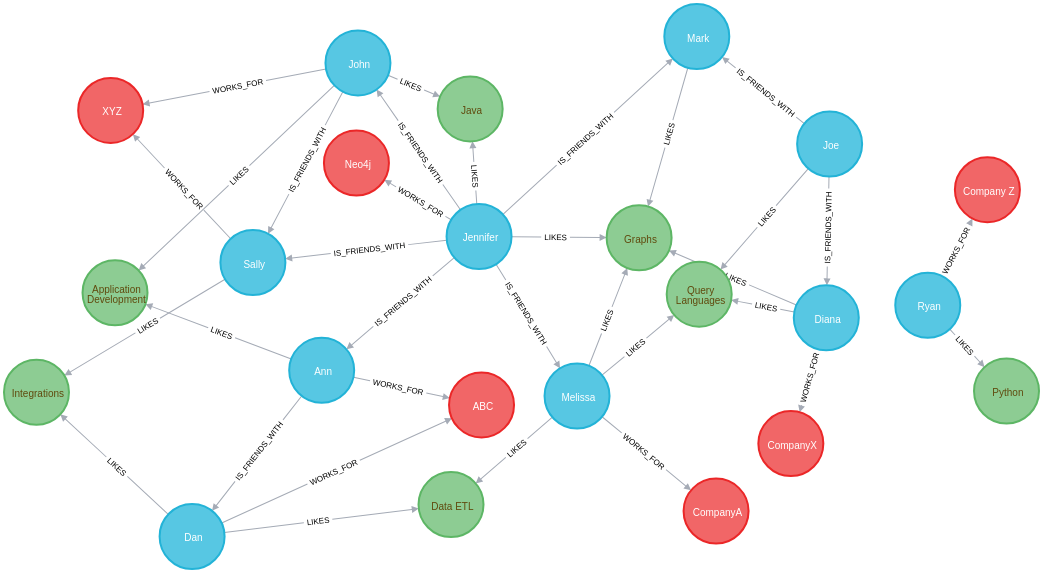
Neo4j에서는 2가지 유형의 서브쿼리 형식을 지원
- WHERE절에 존재하는 하위 쿼리
- CALL {}구문 을 사용하여 하위 쿼리를 반환하는 결과
MATCH (p:Person)-[r:IS_FRIENDS_WITH]->(friend:Person)
WHERE exists((p)-[:WORKS_FOR]->(:Company {name: 'Neo4j'}))
RETURN p, r, friend결과
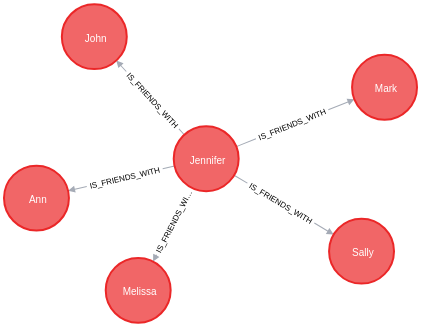
MATCH (p:Person)-[r:IS_FRIENDS_WITH]->(friend:Person)
WHERE EXISTS {
MATCH (p)-[:WORKS_FOR]->(:Company {name: 'Neo4j'})
}
RETURN p, r, friend
MATCH (p:Person)-[:LIKES]->(:Technology {type: "Java"})
RETURN p.name AS person, p.birthdate AS dob
ORDER BY dob DESC
UNION
MATCH (p:Person)
WHERE size((p)-[:IS_FRIENDS_WITH]->()) > 1
RETURN p.name AS person, p.birthdate AS dob
ORDER BY dob DESC;결과
| "Jennifer" | 1988-01-01 |
| "John" | 1985-04-04 |
| "Joe" | 1988-08-08 |
CALL {} 함수를 이용하면 아래와 같은 장점이 존재함
- UNION 접근 방식을 사용하여 개별 쿼리를 실행하고 중복을 제거할 수 있음
- 나중에 결과를 정렬할 수 있음
CALL {}절을 사용하는 쿼리는 다음과 같음
CALL {
MATCH (p:Person)-[:LIKES]->(:Technology {type: "Java"})
RETURN p
UNION
MATCH (p:Person)
WHERE size((p)-[:IS_FRIENDS_WITH]->()) > 1
RETURN p
}
RETURN p.name AS person, p.birthdate AS dob
ORDER BY dob DESC;해당 쿼리를 실행하면 다음과 같은 결과를 얻을 수 있음
| "Joe" | 1988-08-08 |
| "Jennifer" | 1988-01-01 |
| "John" | 1985-04-04 |
참고자료
https://neo4j.com/developer/cypher/querying/
https://neo4j.com/developer/cypher/updating/
https://neo4j.com/developer/cypher/filtering-query-results/
https://neo4j.com/developer/cypher/controlling-query-processing/
https://neo4j.com/developer/cypher/dates-datetimes-durations/
'Database > Graph Database' 카테고리의 다른 글
| TigerGraph GSQL 기초 (2) | 2022.11.19 |
|---|---|
| Cypher 기초(1/2) (0) | 2022.08.20 |
| TigerGraph란? (0) | 2022.05.01 |
| Neo4j DatabaseNotFoundError_status_quarantined (0) | 2022.02.12 |
| Neo4j란? (2) | 2022.02.12 |



