| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- 인공지능
- graph database
- 빅데이터
- Neo4j
- BigData
- GSQL
- Graph Ecosystem
- 그래프
- SparkML
- DeepLearning
- spark
- 그래프 에코시스템
- 그래프 데이터베이스
- Python
- graph
- GraphX
- 그래프 질의언어
- TigerGraph
- 딥러닝
- RStudio
- Federated Learning
- Graph Tech
- TensorFlow
- r
- GDB
- SQL
- RDD
- Cypher
- 연합학습
- 분산 병렬 처리
- Today
- Total
Hee'World
Mapper 클래스 메소드 본문
package org.apache.hadoop.mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
{
protected void setup(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context)
throws IOException, InterruptedException
{
}
// protected void setup(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) : 이 메소드는 map 메소드가 호출되기 전에 먼저 딱 한번 호출되는 메소드로 map 메소드에서 필요한 리소스를 여기서 할당하거나 map에서 필요한 선행 작업을 여기서 수행합니다.
protected void map(KEYIN key, VALUEIN value, Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context)
throws IOException, InterruptedException
{
context.write(key, value);
}
protected void cleanup(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context)
throws IOException, InterruptedException
{
}
// protected void cleanup(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context)
throws IOException, InterruptedException : public void setup 메소드의 반대 역할을 합니다. map함수의 호출이 완료되면, 모든 입력 레코드가 처리되면 마지막으로 한번 호출됩니다. 예를 들어 setup 메소드에서 할당한 리소스가 있으면 여기서 마무리 작업을 하면 됩니다.
public void run(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context)
throws IOException, InterruptedException
{
setup(context);
try {
while (context.nextKeyValue())
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
finally {
cleanup(context);
}
}
// public void run(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context)
throws IOException, InterruptedException : Mapper 클래스의 전체 구동 함수에 해당.
public class Context extends MapContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
{
public Context(TaskAttemptID conf, RecordReader<KEYIN, VALUEIN> taskid, RecordWriter<KEYOUT, VALUEOUT> reader, OutputCommitter writer, StatusReporter committer, InputSplit reporter)
throws IOException, InterruptedException
{
super(taskid, reader, writer, committer, reporter, split);
}
}
}
-- 직접해보는 하둡프로그래밍 참고 --
'BigData > MapReduce' 카테고리의 다른 글
| MapRedcue 컴바이너(Combiner) (0) | 2013.09.05 |
|---|---|
| [1004jonghee]FileInputFormat 종류 (0) | 2013.08.19 |
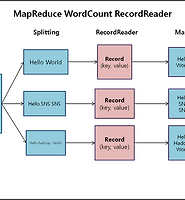
| [1004jonghee]맵리듀스 레코드리더(RecordReader) (0) | 2013.08.13 |
| [1004jonghee]MapReduce란? (0) | 2013.07.30 |