Database/Graph Database
Neo4j란?
Jonghee Jeon
2022. 2. 12. 16:23

Neo4j 특징
- Neo4j는 Neo4j사가 개발한 그래프 데이터베이스 관리 시스템
- Neo4j 개발자들은 네이티브 그래프 저장 및 처리 기능을 갖춘 ACID를 준수하는 트랜잭셔널 데이터베이스로 기술하고 있음
- DB-Engines ranking에 따르면 가장 대중적인 그래프 데이터베이스
- Neo4j는 GPL3 라이선스의 오픈 소스 커뮤니티 에디션으로 이용이 가능(온라인 백업과 고가용 확장 기능(AGPL 라이선스)과 더불어)
- Neo4j는 이러한 확장 기능들이 포함된 Neo4j를 클로즈드 소스 상용 라이선스로 허가
- 자바로 구현되어 있으며 트랜잭셔널 HTTP 엔드포인트를 경유하거나 바이너리 볼트(bolt) 프로토콜을 통해 Cypher Query Language를 사용하여 다른 언어(Python, Java, GoLang 등)로 작성된 소프트웨어로부터 접근이 가능
Neo4j 배경
- Neo4j가 만들어지게 된 배경은 21세기 초 한 미디어 회사의 복잡한 미디어 자산 관리를 위해 기존의 전통적인 기술 스택으로 어려운 문제를 해결하기 위해 새로운 접근 방식을 선택하기 위해 만들어졌음
- 처음에는 그래프 데이터베이스 관리 시스템이기 보다는 그래프 라이브러리에 가까웠으며, 기존 관계형 데이터베이스를 기반으로 사용되었음
- 개발자들은 그래프 추상화 계층의 초점을 맞추기 위해 관계형 데이터베이스에서 벗어나 그래프 저장소를 만들게 되는 결정을 내림
- 그래프 데이터베이스 저장 파일의 바이너리 파일 레이아웃과 같은 저ㅜ준 구성 요소를 포함해 전체 인프라가 그래프 데이터를 처리하도록 최적화되어 개발되어짐
Neo4j Graph Platform
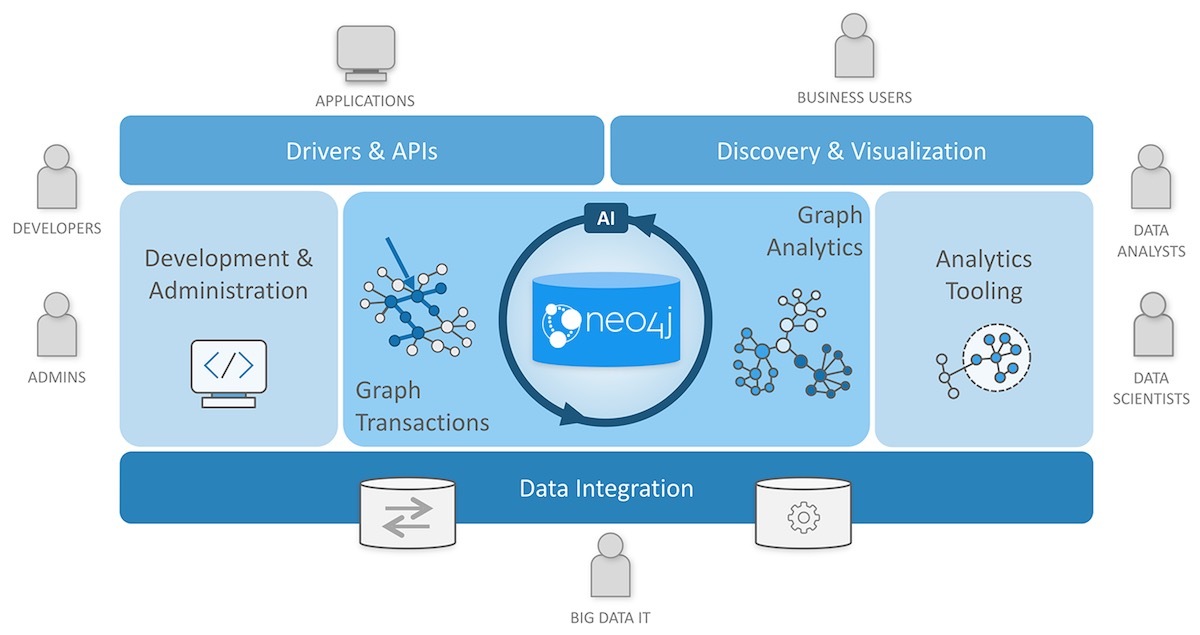
- Neo4j Graph Database - 연결된 데이터를 저장하고 검색하기 위해 구축된 핵심 그래프 데이터베이스이며, Community Edition과 Enterprise Edition의 두 가지 버전이 있음
- Neo4j Desktop - Neo4j의 로컬 인스턴스를 관리하는 애플리케이션이며, 무료 다운로드에는 Neo4j Enterprise Edition 라이선스가 포함됨
- Neo4j Browser - 그래프 데이터베이스의 데이터를 쿼리하고 볼 수 있는 온라인 브라우저 인터페이스이며, Cypher 쿼리 언어를 사용한 기본 시각화 기능 제공
- Neo4j Bloom - 데이터를 보고 분석하는데 코드나 프로그래밍 기술이 필요하지 않은 비즈니스 사용자를 위한 시각화 도구
- Neo4j AuraDB - 클라우드 그래프 데이터베이스를 위한 Neo4j가 제공하는 서비스형 솔루션
- Graph Data Science - Neo4j로 그래프 알고리즘을 실행하기 위해 공식적으로 지원되는 라이브러리이며 엔터프라이즈 워크로드 및 파이프라인에 최적화되어 있음
- APOC - Neo4j에서 제공하는 프로시저 및 함수 표준 유틸리티 라이브러리
GraphQL and GRANDstack - 많이 사용되는 타 데이터 기술 또는 풀 스택 솔루션과 통합가능
ETL Tool - 애플리케이션 및 사용자 인터페이스를 사용하여 관계형 데이터베이스에서 Neo4j로 데이터를 마이그레이션 가능
Cypher
- Cypher는 Neo4j에서 제공하는 선언적 그래프 쿼리 언어
- 그래프의 표현적이고 효율적인 쿼리, 업데이트 및 관리를 허용
- 단순하게 설계되어 개발자와 운영자 모두에게 적합하도록 제공
- 매우 복잡한 데이터베이스 쿼리를 쉽게 표현할 수 있으므로 데이터베이스 액세스에서 도메인에 집중할 수 있음
- Cypher는 다양한 접근 방식에서 영감을 얻었으며 WHERE 및 ORDER BY와 같은 많은 키워드는 SQL에서 영감을 받았고, 패턴 일치는 SPARQL에서 표현 방식을 차용하였음
- 목록 의미 체계 중 일부는 Haskell 및 Python과 같은 언어에서 차용되었음
Cypher 기본 구조
- MATCH: 일치시킬 그래프 패턴. 그래프에서 데이터를 가져오는 가장 일반적인 방법
- WHERE: 그 자체로 구문이 아니라 MACH, OPTION MATCH 및 WITH의 일부이고, 패턴에 제약 조건을 추가하거나 WITH를 통과하는 중간 결과를 필터링함
- RETURN: 결과를 반환
- CREATE(및 DELETE): 노드와 관계를 생성 및 삭제
- SET(및 REMOVE): SET을 사용하여 값을 속성에 설정하고 노드에 레이블을 추가한 다음 REMOVE를 사용하여 제거
- MERGE: 기존 노드 및 패턴을 일치시키거나 새 노드 및 패턴을 생성하고, 고유한 제약 조건과 함께 특히 유용함
Cypher 예시
- CREATE 구문을 이용하여 그래프 생성
CREATE (john:Person {name: 'John'})
CREATE (joe:Person {name: 'Joe'})
CREATE (steve:Person {name: 'Steve'})
CREATE (sara:Person {name: 'Sara'})
CREATE (maria:Person {name: 'Maria'})
CREATE (john)-[:FRIEND]->(joe)-[:FRIEND]->(steve)
CREATE (john)-[:FRIEND]->(sara)-[:FRIEND]->(maria)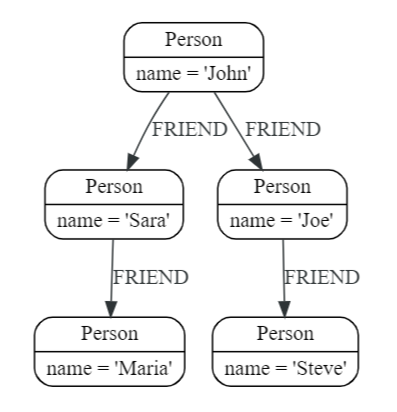
- 'John'과 'John'의 직접 친구가 아닌 관계를 찾는 쿼리
MATCH (john {name: 'John'})-[:FRIEND]->()-[:FRIEND]->(fof)
RETURN john.name, fof.name+----------------------+
| john.name | fof.name |
+----------------------+
| "John" | "Maria" |
| "John" | "Steve" |
+----------------------+
2 rows
- 사용자 이름 목록을 가져와서 이 목록에서 이름이 있는 노드를 모두 찾아 친구를 일치시키고 'name' 속성이 'S'로 시작하는 팔로우 사용자만 반환
MATCH (user)-[:FRIEND]->(follower)
WHERE user.name IN ['Joe', 'John', 'Sara', 'Maria', 'Steve'] AND follower.name =~ 'S.*'
RETURN user.name, follower.name+---------------------------+
| user.name | follower.name |
+---------------------------+
| "John" | "Sara" |
| "Joe" | "Steve" |
+---------------------------+
2 rows
Cypher VS SQL 비교
# SQL
SELECT p.*
FROM products as p;
# Cypher
MATCH (p:Product)
RETURN p;# SQL
SELECT p.ProductName, p.UnitPrice
FROM products as p
ORDER BY p.UnitPrice DESC
LIMIT 10;
#Cypher
MATCH (p:Product)
RETURN p.productName, p.unitPrice
ORDER BY p.unitPrice DESC
LIMIT 10;# SQL
SELECT p.ProductName, p.UnitPrice
FROM products AS p
WHERE p.ProductName = 'Chocolade';
# Cypher 01
MATCH (p:Product)
WHERE p.productName = "Chocolade"
RETURN p.productName, p.unitPrice;
# Cypher 02
MATCH (p:Product {productName:"Chocolade"})
RETURN p.productName, p.unitPrice;# SQL
SELECT p.ProductName, p.UnitPrice
FROM products as p
WHERE p.ProductName IN ('Chocolade','Chai');
# Cypher
MATCH (p:Product)
WHERE p.productName IN ['Chocolade','Chai']
RETURN p.productName, p.unitPrice;# SQL
SELECT p.ProductName, p.UnitPrice
FROM products AS p
WHERE p.ProductName LIKE 'C%' AND p.UnitPrice > 100;
# Cypher
MATCH (p:Product)
WHERE p.productName STARTS WITH "C" AND p.unitPrice > 100
RETURN p.productName, p.unitPrice;# SQL
SELECT DISTINCT c.CompanyName
FROM customers AS c
JOIN orders AS o ON (c.CustomerID = o.CustomerID)
JOIN order_details AS od ON (o.OrderID = od.OrderID)
JOIN products AS p ON (od.ProductID = p.ProductID)
WHERE p.ProductName = 'Chocolade';
# Cypher
MATCH (p:Product {productName:"Chocolade"})<-[:PRODUCT]-(:Order)<-[:PURCHASED]-(c:Customer)
RETURN distinct c.companyName;# SQL
SELECT p.ProductName, sum(od.UnitPrice * od.Quantity) AS Volume
FROM customers AS c
LEFT OUTER JOIN orders AS o ON (c.CustomerID = o.CustomerID)
LEFT OUTER JOIN order_details AS od ON (o.OrderID = od.OrderID)
LEFT OUTER JOIN products AS p ON (od.ProductID = p.ProductID)
WHERE c.CompanyName = 'Drachenblut Delikatessen'
GROUP BY p.ProductName
ORDER BY Volume DESC;
#Cypher
MATCH (c:Customer {companyName:"Drachenblut Delikatessen"})
OPTIONAL MATCH (p:Product)<-[pu:PRODUCT]-(:Order)<-[:PURCHASED]-(c)
RETURN p.productName, toInteger(sum(pu.unitPrice * pu.quantity)) AS volume
ORDER BY volume DESC;# SQL
SELECT e.EmployeeID, count(*) AS Count
FROM Employee AS e
JOIN Order AS o ON (o.EmployeeID = e.EmployeeID)
GROUP BY e.EmployeeID
ORDER BY Count DESC LIMIT 10;
# Cypher
MATCH (:Order)<-[:SOLD]-(e:Employee)
RETURN e.name, count(*) AS cnt
ORDER BY cnt DESC LIMIT 10# SQL
SELECT e.LastName, et.Description
FROM Employee AS e
JOIN EmployeeTerritory AS et ON (et.EmployeeID = e.EmployeeID)
JOIN Territory AS t ON (et.TerritoryID = t.TerritoryID);
# Cypher
MATCH (t:Territory)<-[:IN_TERRITORY]-(e:Employee)
RETURN t.description, collect(e.lastName);# SQL
SELECT p.ProductName
FROM Product AS p
JOIN ProductCategory pc ON (p.CategoryID = pc.CategoryID AND pc.CategoryName = "Dairy Products")
JOIN ProductCategory pc1 ON (p.CategoryID = pc1.CategoryID
JOIN ProductCategory pc2 ON (pc2.ParentID = pc2.CategoryID AND pc2.CategoryName = "Dairy Products")
JOIN ProductCategory pc3 ON (p.CategoryID = pc3.CategoryID
JOIN ProductCategory pc4 ON (pc3.ParentID = pc4.CategoryID)
JOIN ProductCategory pc5 ON (pc4.ParentID = pc5.CategoryID AND pc5.CategoryName = "Dairy Products")
;
# Cypher
MATCH (p:Product)-[:CATEGORY]->(l:ProductCategory)-[:PARENT*0..]-(:ProductCategory {name:"Dairy Products"})
RETURN p.name
OpenCypher
- Neo4j에서 처음 개발되었던 Cypher 질의 언어를 2015년 10월 오픈소스 그래프 질의어로 openCypher 프로젝트를 통해 개방하였고 이를 앞세워 지속적으로 개선되고 있음
참고자료
- https://ko.wikipedia.org/wiki/Neo4j
- https://neo4j.com/developer/graph-platform/
- https://neo4j.com/developer/cypher/intro-cypher/
- https://neo4j.com/docs/cypher-manual/current/introduction/
- https://neo4j.com/developer/cypher/guide-sql-to-cypher/
- https://neo4j.com/blog/open-cypher-sql-for-graphs/
- Neo4j로 시작하는 그래프 데이터베이스 2/e