LipGAN / Wav2Lip
- 최근 영상/음성 합성 기술에 대해 많은 연구와 관심, 그리고 다양한 서비스가 출시되고 그만큼 관련 기술에 대한 발전과 데이터가 무수히 쏟아져 나오고 있음(관련 기업 - 딥브레인, 마인즈랩 등)
- 그 중 영상/음성 합성 기술이 접목되어 있으며 말하는 얼굴 생성(Talking Face Generation)의 대표적인 기술인 LipGAN과 이를 개선한 Wav2Lip을 보고자 함
- LipGAN은 아래에 보여지는 Towards Automatic Face-to-Face Translation라는 논문에서 제안되었음
- 디지털 커뮤니케이션이 활발해지는 최신 트렌드에 맞게 실제 입술 움직임을 동기화하는 파이프라인 제안
- 기존의 알고리즘들을 이용하여 Speech to Speech 번역을 수행하고, 입술의 움직임을 동기화
- LipGAN은 영상과 번역된 오디오를 합성하여 실제 번역된 오디오를 말하는 것과 같은 영상으로 생성

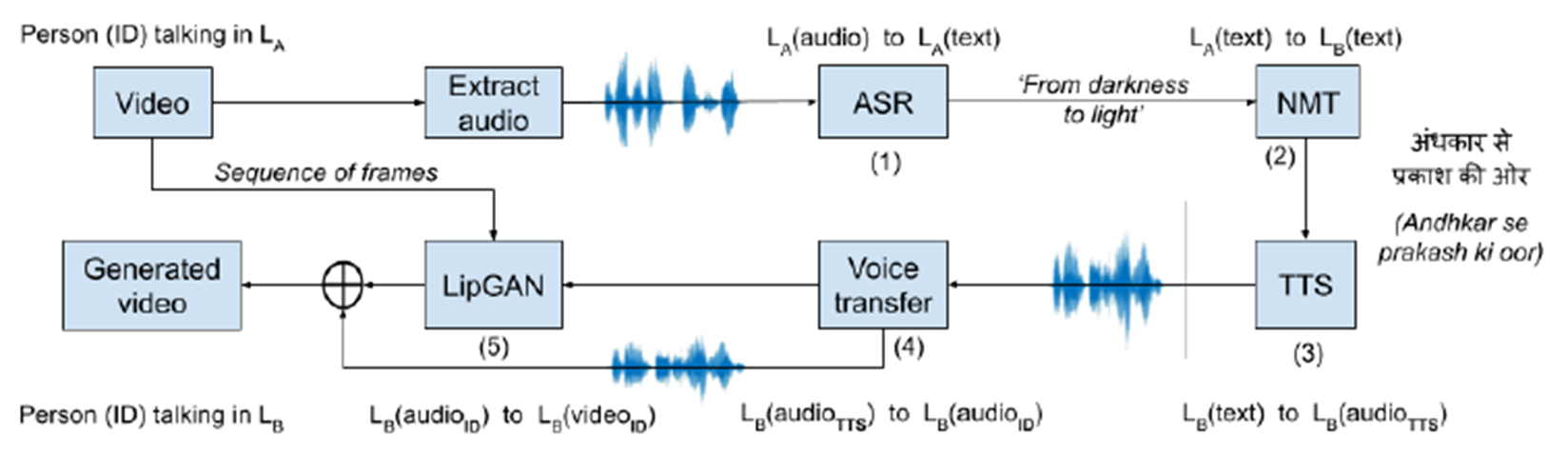
LipGAN 파이프라인 흐름
(1) 소스 언어 LA로 음성인식
(2) LA에서 인식된 텍스트를 대상언어 LB로 번역하고,
(3) 번역된 텍스트의 음성 합성 (3) 합성된 음성에서 LB 언어로 사실적인 말하는 얼굴을 생성
(4) 또한, 스피커를 위한 개인화된 음성을 얻기 위해 음성 전송 모듈 사용
Speech-to-Speech 순서
(1) Langudage L1의 오디오는 DeepSpeech2를 통해 Text로 번역
(2) 변환된 Text는 Transformer 기반의 언어 모델로 번역
(3) 번역된 Text는 DeepVoice3를 통해 Speech로 다시 번역되고, CycleGAN을 사용하여 사용자의 목소리 스타일을 적용
Generator는 Audio encoder, Face encoder, Face decoder로 이루어져 있음
- Audio encoder : 음성 MFCC(Mel-Frequency Cepstral Coefficient)를 고정된 길이의 Vector로 변환
- Face encoder : 영상을 고정된 길이의 Vector로 변환
- Face decoder : 변환된 음성과 영상의 Vector를 concat하여 영상으로 변환
* Face decode에는 Face encoder에 skip connection이 연결되어 있음, Unet구조와 유사
Discriminator는 영상과 음성의 동일 여부를 판단, Audio encoder, Face encoder로 구성되어 있음
두 encode로 같은 길이를 가지는 Vector로 변환하고 L2 loss를 구함

LipGAN에 대한 소스코드와 직접 실행해 볼 수 있는 Github 주소는 아래와 같다.
https://github.com/Rudrabha/LipGAN
GitHub - Rudrabha/LipGAN: This repository contains the codes for LipGAN. LipGAN was published as a part of the paper titled "Tow
This repository contains the codes for LipGAN. LipGAN was published as a part of the paper titled "Towards Automatic Face-to-Face Translation". - GitHub - Rudrabha/LipGAN: This repository...
github.com
LipGAN의 한계
- LipGAN은 음성 신호를 이용하여 얼굴 이미지의 입술 모양을 생성하는 기술인데, 실제로 동영상에 적용해보니 visual artifact나 움직임의 자연성 측면에서 다소 아쉬움이 있었음
- 이를 개선하기 위해서 Discriminator에서 단일 frame이 아니라 복수개의 연속된 frame을 이용하여 temporal correlation을 고려하고, 단순히 contrastive loss가 아니라 visual quality loss라는 것을 사용함으로써 시각적 품질을 개선
- 그들에 따르면, 첫 번째 이유는 이러한 모델(예: L1 재구성 손실 및 LipGAN 판별기 손실)을 훈련할 때 채택된 부적절한 손실 함수이며, 두 번째 이유는 노이즈가 많고 생성된 데이터가 있는 제대로 훈련되지 않은 판별기 네트워크임
- 이러한 문제를 극복하기 위해 연구원들은 학습 문제와 학습 프레임워크를 두 가지 주요 구성 요소, 즉 동기화 손실을 도입한 정확한 립싱크 학습과 시각적 품질 판별기를 통해 시각적 결과를 생성하는 학습으로 분리하는 접근방식을 제안
- 이미 검증된 "전문가" 모델인 SyncNet을 사용하며, SyncNet은 립싱크 오류를 수정하기 위해 만들어짐. 이 모델은 정확성과 안정성을 더욱 향상시키기 위해 생성된 얼굴 비디오와 미세 조정되었음
- 연구자들은 제안된 모델을 단일 데이터 세트인 LRS2에 대해 교육했지만 3개의 추가 데이터 세트를 사용하여 테스트 하였음. 결과는 새로운 Wav2Lip 모델이 기존의 모든 모델을 상당한 차이로 능가함
Wav2Lip
(A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild)

Wav2Lip은 기존 LipGAN 모델과 유사하지만, Pre-trained Lip-Sync Expert와 Visual Quailty Discriminator가 추가됨으로써 입술의 동기화와 시각적인 성능이 향상되었음

- 재구성 손실만 사용하거나 GAN 설정에서 판별기를 훈련시킨 이전 작업과 달리, 립싱크 오류를 탐지하는 데 이미 매우 정확하게 사전 훈련된 판별기를 사용
- 노이즈가 발생한 얼굴에서 이를 미세 조정하면 판별기의 립싱크 측정 능력이 방해되어 생성된 입술 모양에도 영향을 미친다는 것을 보여줌. 또한 시각적 품질 판별기를 사용하여 동기화 정확도와 함께 시각적 품질 개선
Wav2Lip에 대한 소스코드와 실행해 볼 수 있는 Colab은 아래의 Github를 참고하면 됨
https://github.com/Rudrabha/Wav2Lip
GitHub - Rudrabha/Wav2Lip: This repository contains the codes of "A Lip Sync Expert Is All You Need for Speech to Lip Generation
This repository contains the codes of "A Lip Sync Expert Is All You Need for Speech to Lip Generation In the Wild", published at ACM Multimedia 2020. - GitHub - Rudrabha/Wav2Lip: This re...
github.com
Github에 들어가서 Wav2Lip 논문과 데모 영상, Colab Notebook을 바로 사용해 볼 수 있다.

Colab Notebook을 선택하면 아래와 같은 화면이 나오며, 코드를 즉시 실행해 볼 수 있다.

이를 위해서 입력 영상, 입력 오디오, 미리 훈련된 모델이 필요하며, 아래와 같은 순서로 진행하면 된다.
- input_video 준비 -> 구글 드라이브 업로드(Wav2Lip 디렉토리 생성후 업로드)
- input_audio 준비 -> 구글 드라이브 업로드(Wav2Lip 디렉토리 생성후 업로드)
- pre-train model 준비 -> 구글 드라이브 업로드(Wav2lip 디렉토리 생성후 업로드)
-> pre-train model은 Wav2Lip Github에 있는 링크에서 다운로드 가능

다음으로 로그인 되어 있는 현재 구글 계정의 드라이브를 마운트 시킨다.

구글 드라이브 마운트가 완료되면 Wav2Lip을 clone하고 미리 업로드 한 훈련된 모델을 특정 디렉토리로 복사한다.

마지막으로 업로드하였던 입력 영상과 입력 오디오를 이용하여 Wav2Lip을 통해 영상/음성 합성을 수행하면 된다.

참고자료
https://www.notion.so/Towards-Automatic-Face-to-Face-Translation-fccf5b34dc62491bba23cbcfab08edb4
https://smilegate.ai/2020/09/02/body-animation-by-speech/
https://medium.com/deepgamingai/automate-your-lip-sync-animations-with-this-ai-lipgan-ad35551ae62d
https://smilegate.ai/2020/10/07/wav2lip/
https://www.youtube.com/watch?v=Ic0TBhfuOrA