TigerGraph GSQL 기초
GSQL 이란?
TigerGraph 에서 제공하는 그래프 데이터베이스 질의 언어이며 그래프 스키마 설계, 그래프 작성을 위한 데이터 로드 및 관리, 데이터 분석 수행을 위한 그래프 쿼리를 제공함. 즉, TigerGraph 사용자는 GSQL 프로그램을 통해 대부분의 작업을 수행하고 크게, 데이터 정의(Data Definition)와 데이터 로드(Loading (DDL) Language) 부분과 데이터 질의(GSQL Query Language) 부분으로 나뉨
GSQL은 빠르고 확장 가능한 그래프 작업 및 분석을 제공하며 SQL과 GSQL의 유사성이 높은 구문, 튜링 완전성 및 내장된 병렬 처리는 더 빠른 성능, 더 빠른 개발 및 모든 알고리즘을 설명하는 기능을 제공
분석을 위한 설계
GSQL은 복잡한 그래프 분석을 위해 설계되었고, GSQL 쿼리 언어의 고유한 기능인 누산기(accumulators)를 활용함으로써 전통적인 병렬 프로그래밍과 관련된 어려움과 번거로움 없이 TigerGraph의 대규모 병렬 처리(MPP) 기능을 활용할 수 있음
튜링 완료(Turing-complete)
GSQL은 명령형 및 절차형 프로그래밍을 완벽하게 지원하는 Turing-complete로 알고리즘 계산에 이상적입니다. 언어의 튜링 완전성*, 특히 기존 제어 흐름문을 사용하면 사용자가 GSQL로 모든 알고리즘을 설명할 수 있음
* Turing-completeness : 어떤 프로그래밍 언어나 추상 기계가 튜링 기계와 동일한 계산 능력을 가진다는 의미이다. 이것은 튜링 기계로 풀 수 있는 문제, 즉 계산적인 문제를 그 프로그래밍 언어나 추상 기계로 풀 수 있다는 의미이다.(위키백과)
TigerGraph는 커뮤니티 감지를 위한 Louvain 알고리즘 과 복잡한 알고리즘을 설명하는 GSQL의 능력을 보여주는 PageRank 알고리즘을 포함하여 GSQL로 구현된 알고리즘의 오픈소스 그래프 데이터 과학 라이브러리를 제공함
빠른 로딩 및 쿼리
GSQL로 작성된 데이터 로딩 및 쿼리는 TigerGraph의 MPP 기능을 최대한 활용하여 매우 빠른 데이터 수집 및 쿼리를 가능하게 함
벤치마크 테스트 에서 TigerGraph는 LDBC(Data Benchmark Council) SNB(Social Network Benchmark) Scale Factor 30k 데이터 세트를 사용했으며, 결과에 따르면 TigerGraph는 730억 개의 정점(Vertex)과 5340억 개의 에지가 있는 36TB의 원시 데이터에서 딥-링크 OLAP 스타일 쿼리를 몇 분 이내에 결과로 도출함
SQL과 유사
GSQL은 SQL 프로그래머의 학습 곡선을 줄이는 SQL과 유사한 구문을 제공하고 있으며, 아래의 예시는 사전순으로 제품 목록을 검색하는 두 개의 쿼리(SQL, GSQL) 에서 유사점을 볼 수 있음
SQL
SELECT p.*
FROM Product p
ORDER BY p.ProductName;GSQL
CREATE QUERY products_abc() {
products = {Product.*};
results =
SELECT p
FROM products:p
ORDER BY p.productName;
PRINT results;
}GSQL 기초
GSQL을 이용하여 데이터를 정의하고 로드하는 순서는 다음과 같음
- Vertex 생성 - CREATE VERTEX vertex명 (PRIMAR_ID 속성, 속성1, 속성2, ...) 으로 생성
- Edge 생성 - CREATE DIRECTED/UNDIRECTED EDGE edge명 (FROM VERTEX명, TO VERTEX명, Edge 속성1, ..) 으로 생성
- Graph 생성 - CREATE GRAPH graph명(vertex명, edge명)으로 앞서 생성한 Vertex와 Edge를 선택하여 그래프의 구성요소로 생성
- Job 생성(Vertex/Edge 데이터 매핑)
- Job 실행(데이터 로드)
데이터 정의 예시(Define a Schema - GSQL 101)
GSQL > CREATE VERTEX Person (PRIMARY_ID name STRING, name STRING, age INT, gender STRING, state STRING)
Successfully created vertex types: [Person].GSQL > CREATE UNDIRECTED EDGE Friendship (FROM Person, TO Person, connect_day DATETIME)
Successfully created edge types: [Friendship].
GSQL >GSQL > CREATE GRAPH Social (Person, Friendship)
Stopping GPE GSE RESTPP
Successfully stopped GPE GSE RESTPP in 16.554 seconds
Starting GPE GSE RESTPP
Successfully started GPE GSE RESTPP in 0.119 seconds
The graph Social is created.- 생성된 GRAPH 조회 예시(GSQL shell)
GSQL > ls
---- Graph Social
Vertex Types:
- VERTEX Person(PRIMARY_ID name STRING, name STRING, age INT, gender STRING, state STRING) WITH STATS="OUTDEGREE_BY_EDGETYPE"
Edge Types:
- UNDIRECTED EDGE Friendship(FROM Person, TO Person, connect_day DATETIME)
Graphs:
- Graph Social(Person:v, Friendship:e)
Jobs:
Queries:
데이터 로드 예시(Load Data - GSQL 101)
USE GRAPH Social
BEGIN
CREATE LOADING JOB load_social FOR GRAPH Social {
DEFINE FILENAME file1="/home/tigergraph/tutorial/3.x/gsql101/person.csv";
DEFINE FILENAME file2="/home/tigergraph/tutorial/3.x/gsql101/friendship.csv";
LOAD file1 TO VERTEX Person VALUES ($"name", $"name", $"age", $"gender", $"state") USING header="true", separator=",";
LOAD file2 TO EDGE Friendship VALUES ($0, $1, $2) USING header="true", separator=",";
}
ENDJOB 생성 명령어 :
- USE GRAPH Social: JOB 생성을 수행하는 그래프
- BEGIN … END: 다중 라인 모드. GSQL 쉘은 마커 사이의 모든 것을 단일 명령문으로 취급. 이는 대화식 모드에만 필요하며, 명령 파일에 저장된 GSQL 문을 실행하면 명령 인터프리터가 전체 파일을 연구하므로 BEGIN 및 END 힌트가 필요하지 않음
- CREATE LOADING JOB: 하나의 로드 작업으로 여러 파일에서 여러 그래프 개체로의 매핑을 수행할 수 있음. 각 파일은 파일 이름 변수에 할당되어야 하며, 필드 레이블은 이름 또는 위치로 지정할 수 있음. 이름별 레이블 지정에는 소스 파일에 헤더 행이 필요하고, 위치별 레이블은 정수를 사용하여 소스 열 위치함( 0, 1,.. ,...)
- PRIMARY_ID Person 의 "이름" 열 은 정점 의 "이름" 속성과 file1두 필드에 매핑
- file1에서는 성별이 나이보다 먼저 나오며, Person VERTEX에서 성별은 나이 다음에 나옴. 로드할 때 대상 개체(이 경우 Person VERTEX) 에 필요한 순서대로 속성을 지정
- 각 LOAD문에는 USING절이 있으며, 여기에서 두 파일 모두 헤더가 포함되어 있음을 GSQL에 알려줌(이름 사용 여부에 관계없이 GSQL은 여전히 첫 번째 행을 데이터로 간주할지 여부를 알아야 함). 또한 열 구분 기호가 쉼표라고 알려주며, GSQL은 쉼표뿐만 아니라 모든 단일 문자 구분 기호를 처리할 수 있음
명령문을 실행할 때 CREATE LOADING JOB GSQL은 구문 오류를 확인하고 지정된 위치에 데이터 파일이 있는지 확인 한 뒤에 오류가 감지되지 않으면 작업을 컴파일하고 저장함
GSQL > run loading job load_social
[Tip: Use "CTRL + C" to stop displaying the loading status update, then use "SHOW LOADING STATUS jobid" to track the loading progress again]
[Tip: Manage loading jobs with "ABORT/RESUME LOADING JOB jobid"]
Starting the following job, i.e.
JobName: load_social, jobid: social_m1.1528095850854
Loading log: '/home/tigergraph/tigergraph/logs/restpp/restpp_loader_logs/social/social_m1.1528095850854.log'
Job "social_m1.1528095850854" loading status
[FINISHED] m1 ( Finished: 2 / Total: 2 )
[LOADED]
+---------------------------------------------------------------------------+
| FILENAME | LOADED LINES | AVG SPEED | DURATION|
|/home/tigergraph/friendship.csv | 8 | 8 l/s | 1.00 s|
| /home/tigergraph/person.csv | 8 | 7 l/s | 1.00 s|
+---------------------------------------------------------------------------+GSQL Pattern Matching Tutorial
Prepare your environment - Pattern Matching tutorial
LDBC Social Network Benchmark (LDBC SNB) data set.
그래프 패턴은 VERTEX 유형 집합과 EDGE 유형으로 연결되는 방식을 지정하며, 그래프 패턴은 일반적으로 쿼리 구조의 가장 기본적인 부분인 FROM절에 나타내며, WHERE절의 조건을 사용하여 패턴을 더 세분화할 수 있음
One-hop patterns 예시
- Message HAS_CREATOR Person
Person:p -(LIKES>:e)- Message:m
Person:p -(<HAS_CREATOR:e)- Message:mUSE GRAPH ldbc_snb
INTERPRET QUERY () SYNTAX v2 {
// 1-hop pattern.
friends = SELECT p
FROM Person:s -(Knows:e)- Person:p
WHERE s.first_name == "Viktor" AND s.last_name == "Akhiezer"
ORDER BY p.birthday ASC
LIMIT 3;
PRINT friends[friends.first_name, friends.last_name, friends.birthday];
}USE GRAPH ldbc_snb
INTERPRET QUERY () SYNTAX v2 {
SumAccum<int> @comment_cnt= 0;
SumAccum<int> @post_cnt= 0;
// 1-hop pattern.
Result = SELECT s
FROM Person:s -(Likes>)- :tgt
WHERE s.first_name == "Viktor" AND s.last_name == "Akhiezer"
ACCUM CASE WHEN tgt.type == "Comment" THEN
s.@comment_cnt += 1
WHEN tgt.type == "Post" THEN
s.@post_cnt += 1
END;
PRINT Result[Result.@comment_cnt, Result.@post_cnt];
}반복 패턴(Repeating a 1-Hop Pattern)
USE GRAPH ldbc_snb
INTERPRET QUERY () SYNTAX v2 {
tag_class1 = SELECT t
FROM Tag_Class:s - (Is_Subclass_Of>*) - Tag_Class:t
WHERE s.name == "TennisPlayer";
PRINT tag_class1;
}USE GRAPH ldbc_snb
INTERPRET QUERY () SYNTAX v2 {
tag_class1 = SELECT t
FROM Tag_Class:s - (Is_Subclass_Of>*1) - Tag_Class:t
WHERE s.name == "TennisPlayer";
PRINT tag_class1;
}USE GRAPH ldbc_snb
INTERPRET QUERY () SYNTAX v2 {
tag_class1 = SELECT t
FROM Tag_Class:s - (Is_Subclass_Of>*1..2) - Tag_Class:t
WHERE s.name == "TennisPlayer";
PRINT tag_class1;
}USE GRAPH ldbc_snb
INTERPRET QUERY () SYNTAX v2 {
tag_class1 = SELECT t
FROM Tag_Class:s - (Is_Subclass_Of>*..2) - Tag_Class:t
WHERE s.name == "TennisPlayer";
PRINT tag_class1;
}USE GRAPH ldbc_snb
INTERPRET QUERY () SYNTAX v2 {
tag_class1 = SELECT t
FROM Tag_Class:s - (Is_Subclass_Of>*1..) - Tag_Class:t
WHERE s.name == "TennisPlayer";
PRINT tag_class1;
}USE GRAPH ldbc_snb
INTERPRET QUERY () SYNTAX v2{
SumAccum<INT> @@comment_cnt = 0;
// find top 3 latest comments that is liked or created by Viktor Akhiezer
// and the total number of comments related to Viktor Akhiezer
top_3_comments = SELECT p
FROM Person:s - ((<Has_Creator|Likes>)*1) - Comment:p
WHERE s.first_name == "Viktor" AND s.last_name == "Akhiezer"
ACCUM @@comment_cnt += 1
ORDER BY p.creation_date DESC
LIMIT 3;
PRINT top_3_comments;
// total number of comments related to Viktor Akhiezer
PRINT @@comment_cnt;
}
Multiple Hop Pattern
패턴 매칭의 진정한 힘은 각 홉의 특성을 가진 멀티 홉 패턴을 표현하는 데 있음. 예를 들어, 잘 알려진 상품 추천 문구 "이 상품을 구매한 사람들은 이 상품도 구매했습니다"는 다음과 같은 2홉 패턴으로 표현됨
FROM This_Product:p -(<Bought:b1)- Customer:c -(Bought>:b2)- Product:p2
WHERE p2 != p보시다시피 2홉 패턴은 두 패턴이 공통 끝점을 공유하는 두 개의 1홉 패턴을 단순 연결 및 병합한 것이며, 아래에서 Y:y는 연결 끝점이고 일반적으로 N개의 1-홉 패턴을 N-홉 패턴으로 연결할 수 있음
3홉 패턴
FROM X:x - (E2>:e2) - Y:y - (<E3:e3) - Z:z - (E4:e4) - U:uUSE GRAPH ldbc_snb
INTERPRET QUERY () SYNTAX v2 {
Tag_Class1 =
SELECT t
FROM Tag_Class:s-(Is_Subclass_Of>.Is_Subclass_Of>.Is_Subclass_Of>)-Tag_Class:t
WHERE s.name == "TennisPlayer";
PRINT Tag_Class1;
}Accumulators(누산기)
GSQL은 튜링 완전 그래프 데이터베이스 쿼리 언어입니다. 다른 그래프 쿼리 언어와 비교할 때 가장 큰 장점은 누적기(글로벌 또는 정점 로컬)를 지원한다는 것입니다.
이해하기 쉬운 패턴 일치 구문 외에도 GSQL은 전역 누산기라는 전역 상태 변수뿐만 아니라 런타임 정점 속성인 정점 부착 누산기를 지원합니다.
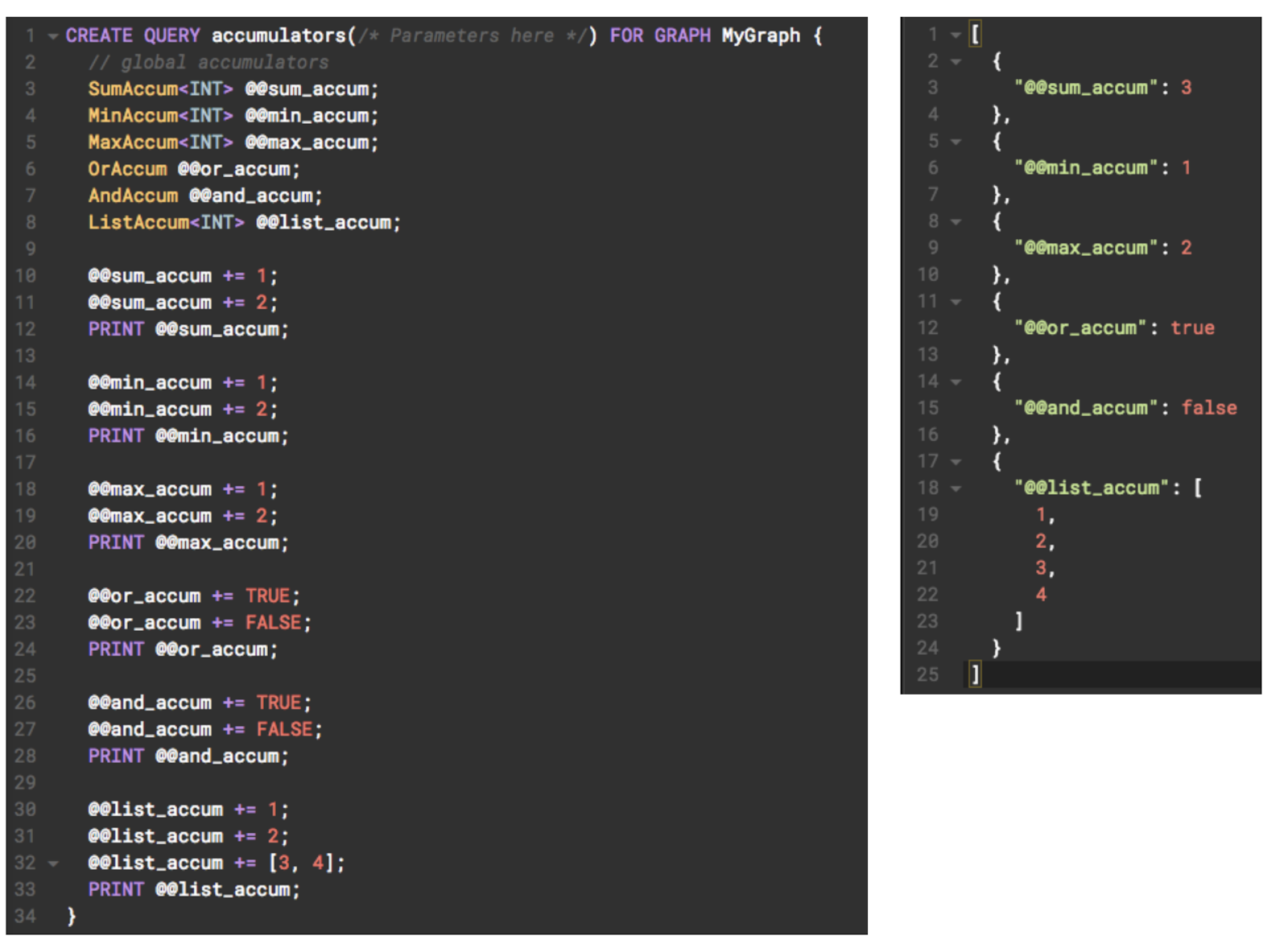
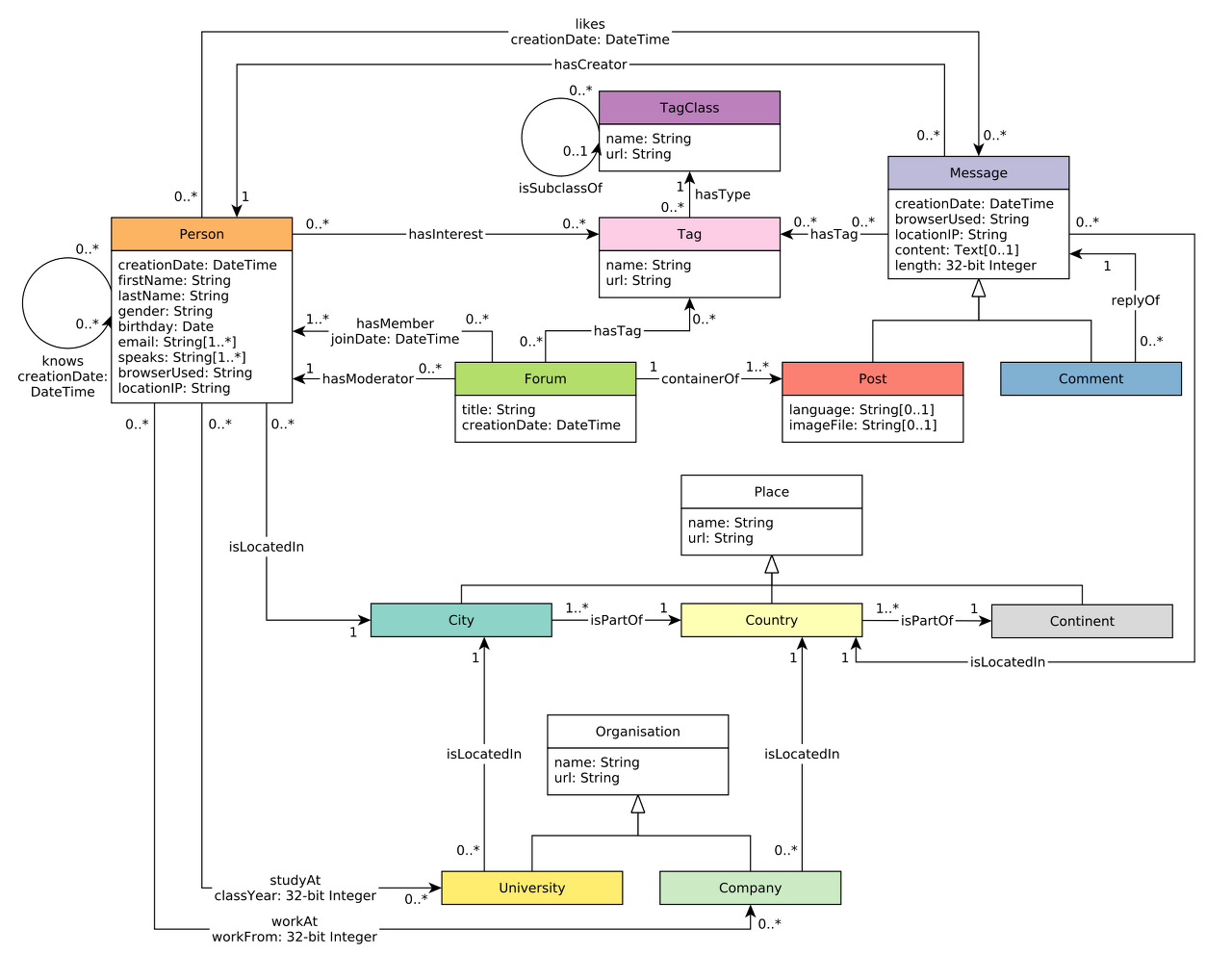
누산기는 GSQL의 상태 변수이며 상태는 쿼리의 수명 주기 동안 변경 가능함. 초기값이 있으며 사용자는 "=" 내장 연산자를 사용하여 새로운 값을 계속 축적할 수 있음. 각 누산기 변수에는 유형이 있고, 유형은 선언된 누산기가 "=" 연산을 해석하는 데 사용할 의미 체계를 결정함
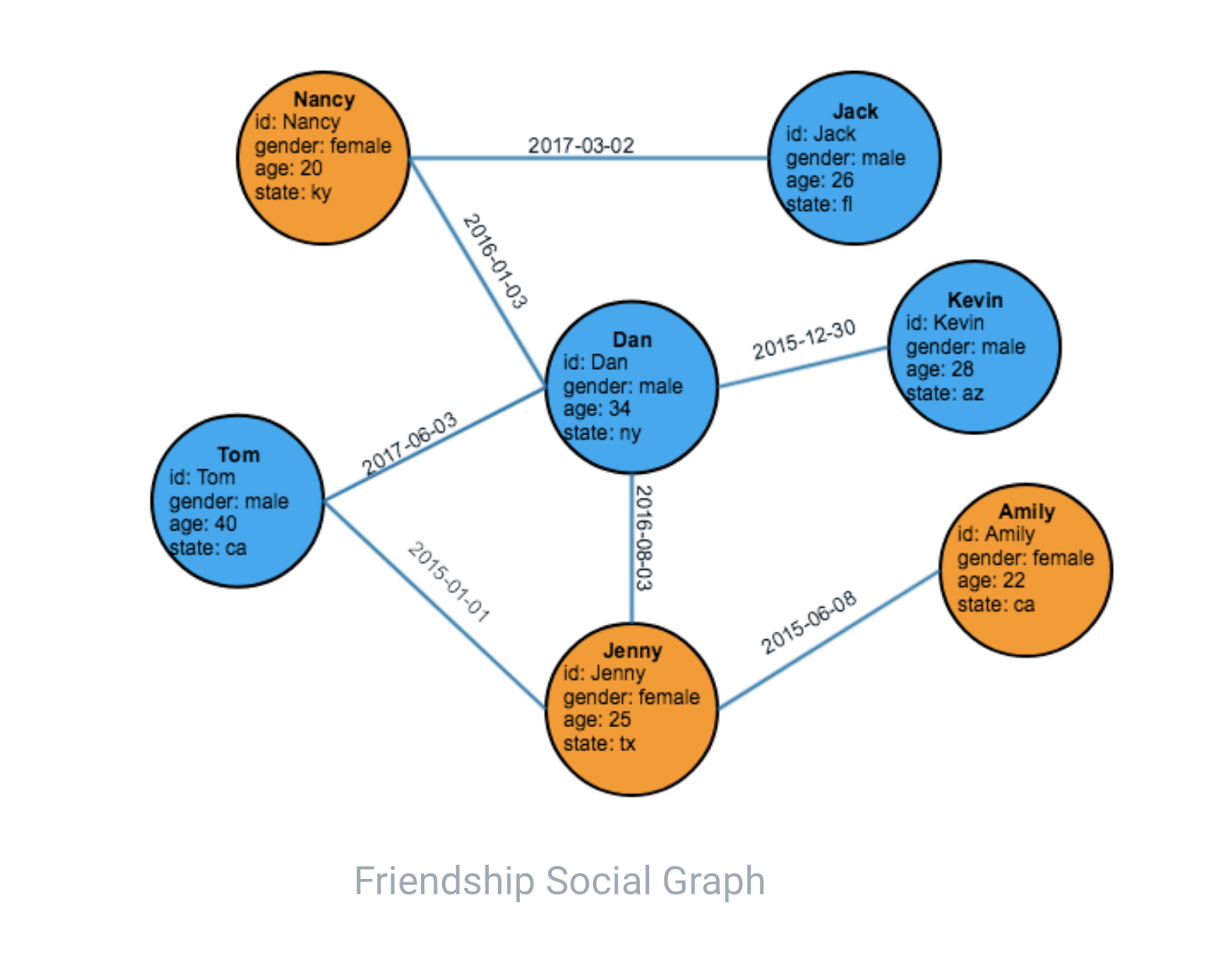
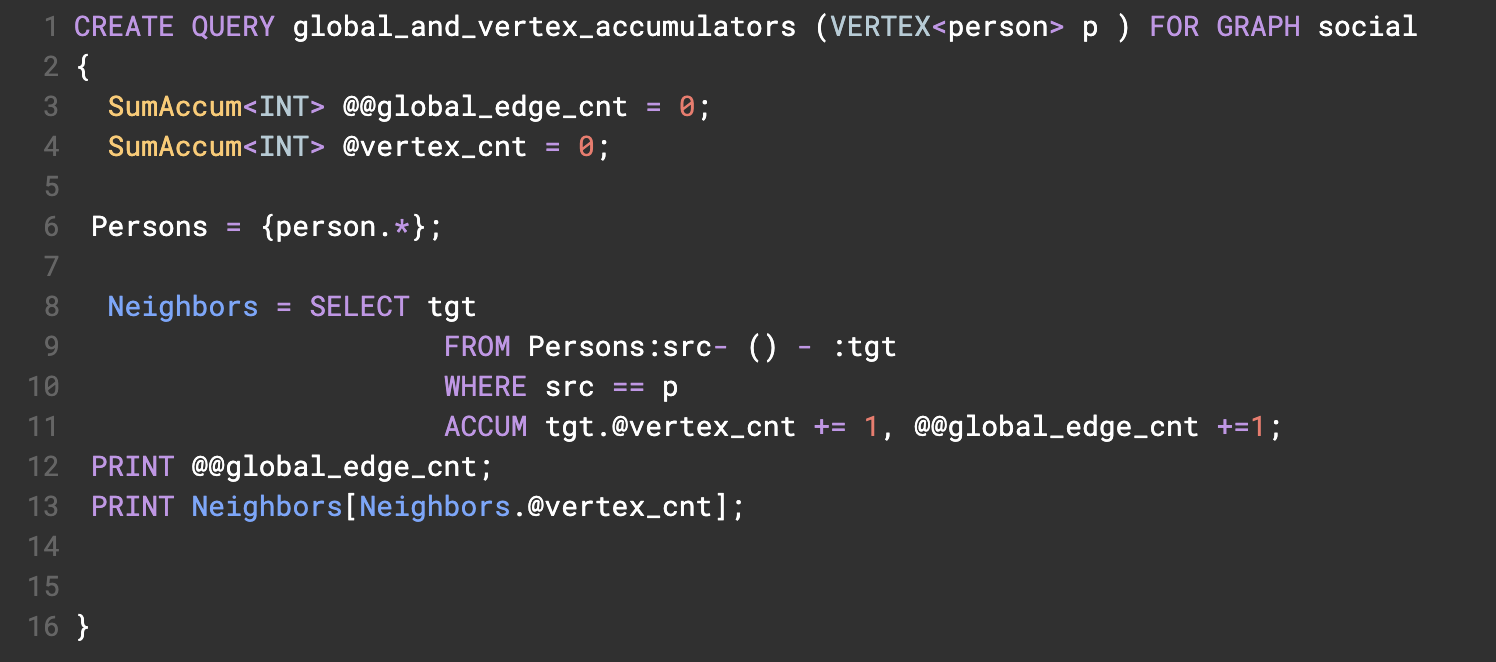
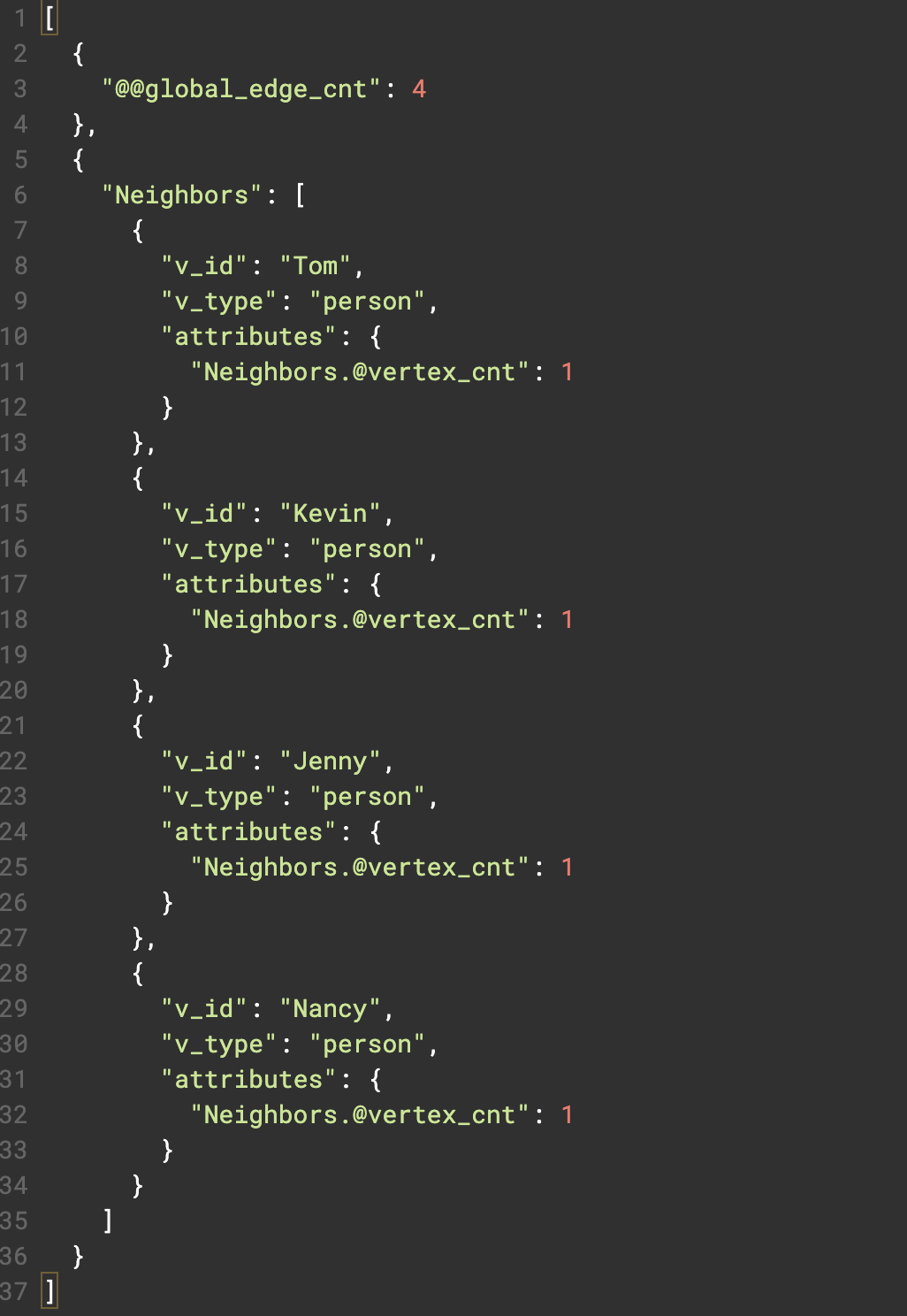
그림 2에 표시된 사람 정점 유형과 개인 간 우정 에지 유형으로 모델링된 소셜 그래프를 예로 들면, 아래에서 사람을 받아들이고 입력 사람에서 해당 사람으로 1홉 순회를 수행하는 쿼리를 수행함.
@@global_edge_cnt 누산기를 사용하여 연결되는 총 에지 수를 누적하고 @vertex_cnt를 사용하여 입력한 사람의 각 친구 정점에 정수 1을 + 함.
참고자료
https://docs.tigergraph.com/gsql-ref/current/tutorials/gsql-101/
GSQL 101 - GSQL Language Reference
A beginner tutorial to get started with GSQL.
docs.tigergraph.com